

A development team developing for the cloud faces a slew of new challenges, ranging from an adapted development process to new methodologies and frameworks. However, a shift in task distribution is also being discussed. Many projects are still deciding which new duties the developers will take on. Is it better if these additional tasks are handled by the operations team? Finally, new tools to support the additional work steps in the development process must be considered.
The topic is extensive, and in some areas, the DevOps community is still in the early stages or in the midst of change. As a result, highlighting all of the important aspects is challenging. With this in mind, we intend to choose a few topics and examine them in greater depth. Some of them will be discussed in greater detail, while others will be mentioned briefly.
STAY TUNED
Learn more about DevOpsCon
Development process
When developing applications for the cloud, developers must not only deal with new architectural approaches but also with new infrastructure requirements. To meet these requirements, new substeps in the development process are required. The application must be able to run in a Docker container, which is operated in an orchestration environment such as Kubernetes. As a result, the traditional development process is supplemented with the substeps “Docker Build and Push” and “Deploy to (local) K8S.” Figure 1 depicts the new development process for a cloud-native application.
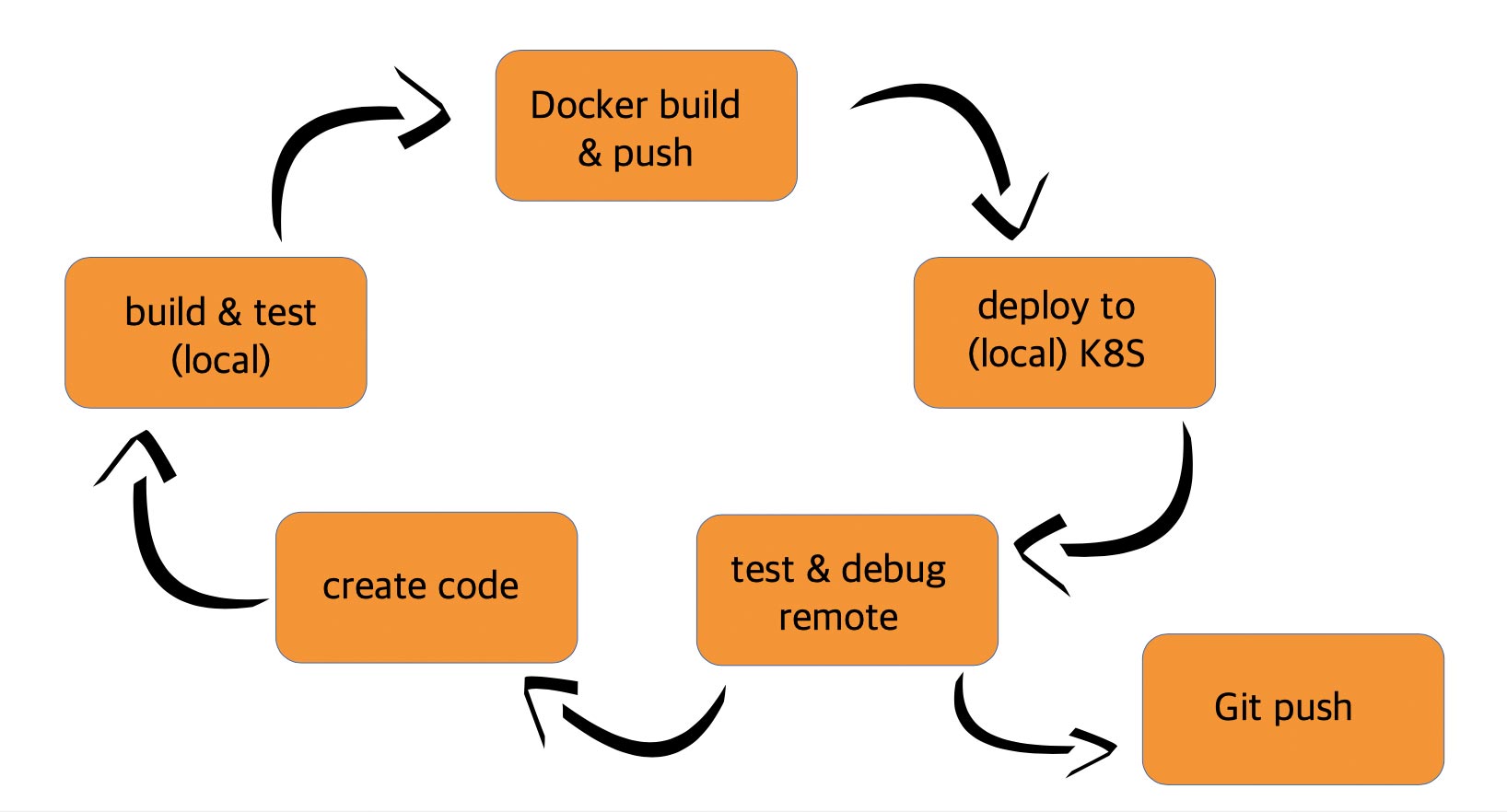
Fig. 1: Cloud-native development process
This extended development process invariably requires the use of new tools. Be it because the old tools no longer fit, or because there are new substeps in the process that were not previously required. To continue developing efficiently, the goal should always be to achieve the highest level of automation possible. We will come back to the topic of tool selection later. “Deploy to (local) K8S” will also be covered in greater detail in one of the following sections.
DevOps task distribution
In addition to the new development process, there are also new tasks. In the past, for example, you would hand over an installation instruction in prose to your Ops colleagues. Based on this description, they would try to deploy and operate the application. As a result of this approach, the outcome was often faulty because the prose descriptions were misunderstood or formulated in a misleading way.
Fortunately, these mistakes taught us valuable lessons. Declarative manifest files, such as those used in Kubernetes, clearly define what the application needs from the runtime environment to function properly. Misunderstandings are ruled out here.
This new approach inevitably leads to a new task. The question is, who in the project/company is in charge of creating these manifest files? On the one hand, it is clearly the developer’s responsibility. He understands what resources (database connections, environment variables, CPU and memory consumption, etc.) his application needs. On the other hand, these manifest files include many aspects that come from the operating platform (autoscaling, storage, load balancing, networking, etc.). This requires knowledge that was previously reserved for Ops colleagues but is now frequently found in so-called cloud platform teams. These manifest files must incorporate knowledge from both the Dev and Ops worlds. As a result, intense discussions are taking place in projects/companies about how to best distribute tasks.
The approaches to the solution here range from “the Ops team only provides Kubernetes as a platform,” “the Ops team develops base manifest files to support the Dev team,” and “the DevOps team is solely responsible and accountable for the application.” In any case, working shoulder to shoulder with the Ops colleagues/platform team to find an individual and workable approach is required. This is a good thing because it aligns with the DevOps philosophy.
From a technical standpoint, Helm [1], as a so-called package manager, provides the ability to create base charts. Base manifest files are made available, which can then be integrated and parameterized into the user’s own Helm charts. As a result, a multi-level hierarchical chart-in-chart structure is created. The art is in determining the best approach for the following questions: What should be predefined in the base chart, what can be parameterized, and what is up to the base chart user? Which base chart structure is best suited to our project/business?
If the creation of the respective base charts is organised as an InnerSource project, a suitable set of charts is usually obtained very quickly, greatly simplifying life for the development teams.

Cloud provider dependencies
Each of the well-known cloud providers (AWS, Azure, Google, etc.) has different X-as-a-Service offerings in its programme. That is, various cloud computing services are made available to make it easier to get started, but also to deal with the cloud. The more X-as-a-Service services are used, the less one has to deal with them alone. This shifts the distribution of previously outlined tasks further in the direction of the cloud provider, relieving the Ops team of such tasks.
These offers seem so appealing at first glance, but you must be aware that you become heavily dependent on the cloud provider. Because the service offerings are highly proprietary, switching cloud providers is difficult.
To address this issue, so-called multi-cloud strategies are being implemented more frequently. For the same reason, there are now legal requirements and guidelines that enable users to switch cloud providers at any time.
Twelve-Factor App [2]
The “Twelve-Factor App” method, developed years ago, offers useful recommendations on what should be considered when creating a software-as-a-service application. The following principles form the basis for the twelve factors:
- declarative formats for automated installation
- unique contract with the operating system for maximum portability
- deployment in modern cloud platforms
- minimal difference between development and production environments for continuous deployment
- flexibility for changes in tooling, architecture, or deployment
Twelve concrete factors with very clear instructions for action were derived from these principles. Following these instructions results in an application that meets the requirements of cloud systems. Listing and describing these twelve factors would be beyond the scope of this article, so every development team should read up on them and incorporate them into their own projects.
One particular factor, number ten, “Dev/prod parity,” will be discussed in greater depth later in the article.
Developer frameworks and JVM
Aside from operations, there has been a lot of activity in the cloud environment on the developer side as well. Spring began developing new frameworks for cloud development very early on. Unfortunately, new frameworks for Java EE and Jakarta EE developers took a little longer to emerge. It was not until the creation of MicroProfile [3] that Jakarta EE applications could be developed for the cloud.
Unfortunately, startup times for Spring and MicroProfile applications are extremely long. On the other hand, one significant advantage of the cloud is that peak loads can be handled very elegantly through autoscaling. In JVM-based systems, new technologies have emerged to mitigate this disadvantage. As a result, Oracle has started work on GraalVM [4]. At its core is a compiler that converts Java code to fast executable and compact binary code. Quarkus [5] has also joined the fight against lengthy startup times. Quarkus describes itself as a Kubernetes-native Java stack that is tailor-made for OpenJDK, HotSpot, and GraalVM. Quarkus is also a MicroProfile-certified application server that supports native compilation by GraalVM to produce high-performance and resource-efficient application code.
Tools
If you are at the beginning of your journey into cloud development or want an up-to-date overview of the tools available, the CNCF Landscape [6] is a good place to start. Particularly under the headings “Application Definition & Image Build” and “Continuous Integration & Delivery,” you will find a large selection of useful and necessary Dev(Ops) tools. If you choose one of the tools listed here, there is a good chance that it will still be up-to-date and available tomorrow. After all, you don’t want to be constantly changing a well-established and functional toolchain.
In addition to so-called experience, when selecting tools, you should consider how the tools can be integrated into the existing development process. Are standardised transfer interfaces in the direction of upstream or downstream tools supported, or is integration into the overall process rather awkward? After all, despite all the risk protection provided by the CNCF Landscape, situations may arise in which one tool must be replaced by another. This may be because the tool has reached its end of life or because a better tool has become available to replace it.
Over the last few years, companies’ tool selection policies have changed significantly. Previously, there were always rules coming from above dictating which tools developers could use. Fortunately, these rules are becoming less common. After all, the developer should be the one to decide which tools he/she will use on a daily basis. In the end, the so-called tool Darwinism prevails. Among developers, word quickly spreads about which tool truly does a good job. In the end, only one tool usually becomes the standard within a project or a company. This is not to say that a company’s specifications are completely off the table.
As in the past, there are still tool manufacturers that offer commercial tools for this purpose. Typically, open-source projects are the basis for this. On top of this, additional special functions are offered commercially. In most cases, the basic functions provided by open-source projects are sufficient. Therefore, each team must decide whether these commercial offers are worthwhile or whether to start with open source.
Tools in the development process
From a Dev(Ops) Experience perspective, the “Application Definition & Image Build” and “Continuous Integration & Delivery” sections contain the most important tools. Those are the tools that a developer is most likely to use. But, before we get into the tools, let’s take another look at the development process.
In short, the new development process revolves around the following challenge: “How do I get my code to the cloud as quickly as possible?” Because the additional steps extend the roundtrip time, a fast roundtrip is now even more important than before. Erroneous intermediate results, which can occur more often due to the more extensive process, also increase the roundtrip.
The developer typically creates the artefacts required for this (Docker image, manifest files). Therefore, it stands to reason that these artefacts should be created and tested on the local development machine. The developer needs to be able to verify that his Helm Charts are generating the correct manifest files or that the Docker image meets the required specifications. If these steps only take place on the CI server, the turnaround time is increased and efficiency is not particularly high. The silver bullet is to use the same tools on the development machine and on the CI server.
The creation of the Docker image is a new required step in the development process. The simplest way to accomplish this is to use a corresponding Gradle or Maven plug-in. But proceed with caution: A major plug-in die-off has occurred in recent years. Only a few of the previously more than ten available plug-ins remain. The best known are docker-maven-plugin [8] and jib [9]. Gradle appears to be in a similar state: Docker Gradle Plugin by Palantir [10], Benjamin Muschko [11], or jib [12] are the last available alternatives.
On the other hand, some tools, known as stand-alone tools, can take over the creation of the Docker image. In addition to Docker [13], these include Kaniko [14] and Buildah [15], to name a few examples. However, this immediately raises the question of how to run them on the developer machine in an automated manner after the application has been built. This is less difficult to implement on the CI server.
CI/CD-Server
New CI/CD servers have emerged in recent years, adapted to the cloud’s new capabilities or requirements. The CNCF Landscape pool includes Argo, Flux, Keptn, JenkinsX, and Tekton, to name a few.
Testing and debugging
Testing and debugging of an application can be performed locally to a large extent. However, there is a clear need to test and possibly debug the application in the target environment, i.e. the Kubernetes cluster. There are some differences between the local development environment and the cluster that can cause the application to behave differently, such as:
- operating system
- JDK version
- environment variables, volume mounts, DNS…
- backing service with cluster configuration (local single server configuration only)
When the application behaves differently in the cluster than in the local test, determining the cause becomes costly. Fortunately, there are a number of approaches that can help with this. They are as follows:
- synchronous deployment
- source reload
- swap deployment
These three approaches are discussed further below.

Better Continuous Delivery with microservices
Explore the Continuous Delivery & Automation Track
Synchronous deployment
The first approach is synchronous deployment. Skaffold [16], for example, synchronises the code locally and in the cluster. It starts the necessary build steps in the background as soon as the code changes locally, and it also handles the deployment in the cluster. Long-running tests can be temporarily deactivated during the build. As a result, the new code state is deployed in the cluster in a matter of seconds, and a test can immediately determine whether the error has been fixed. This tool is extremely useful, especially during the initial phase when developers have to take care of the Docker image or Kubernetes manifest files.
Source reload
The source reload is another option for a quick pass from compile to deployment. Here, new locally compiled class files are uploaded to the running Kubernetes pod. The application server in the pod swaps out these class files on the fly without restarting the server. The new code is executed on the next test call, which should hopefully fix the bug.
There are a few prerequisites for this. First, the application server must provide this functionality, which is almost always the case with the most widely used servers (Tomcat, OpenLiberty, etc.). A quick look through the documentation should confirm this and explain the required settings. You will, however, require a tool that allows you to transfer class files. This is where Ksync [17] comes into play. Ksync synchronises the local file system, which contains the class files after compilation, in the running Kubernetes pod. After Ksync has placed the new files in the pod, they are loaded from the application server. The entire process is very fast because it is usually just a few small files that can be copied to the cluster without taking much time. The whole thing would also work with a WAR file, but it would be a little slower due to the additional build step and the size of the WAR file.
The same approach is used by Quarkus’ so-called live coding. A properly configured app server exchanges received class files on the fly without restarting. Quarkus also provides the necessary local sync process. Quarkus thus supports a source reload without the use of additional tools.
A code replacement without restart has the advantage of not breaking an existing remote debug connection. This gives the developer an experience that is nearly identical to local development, even when debugging.
Swap deployment
The third approach goes one step further. A bidirectional proxy replaces the Kubernetes pod in which the application is running. This proxy is configured to forward requests to the locally running instance of the application. The local network on the development machine is also changed. As a result, the responses can be routed back to the Kubernetes cluster. T The proxy receives them and forwards them accordingly. The diagram in Figure 2 is intended to illustrate this situation.
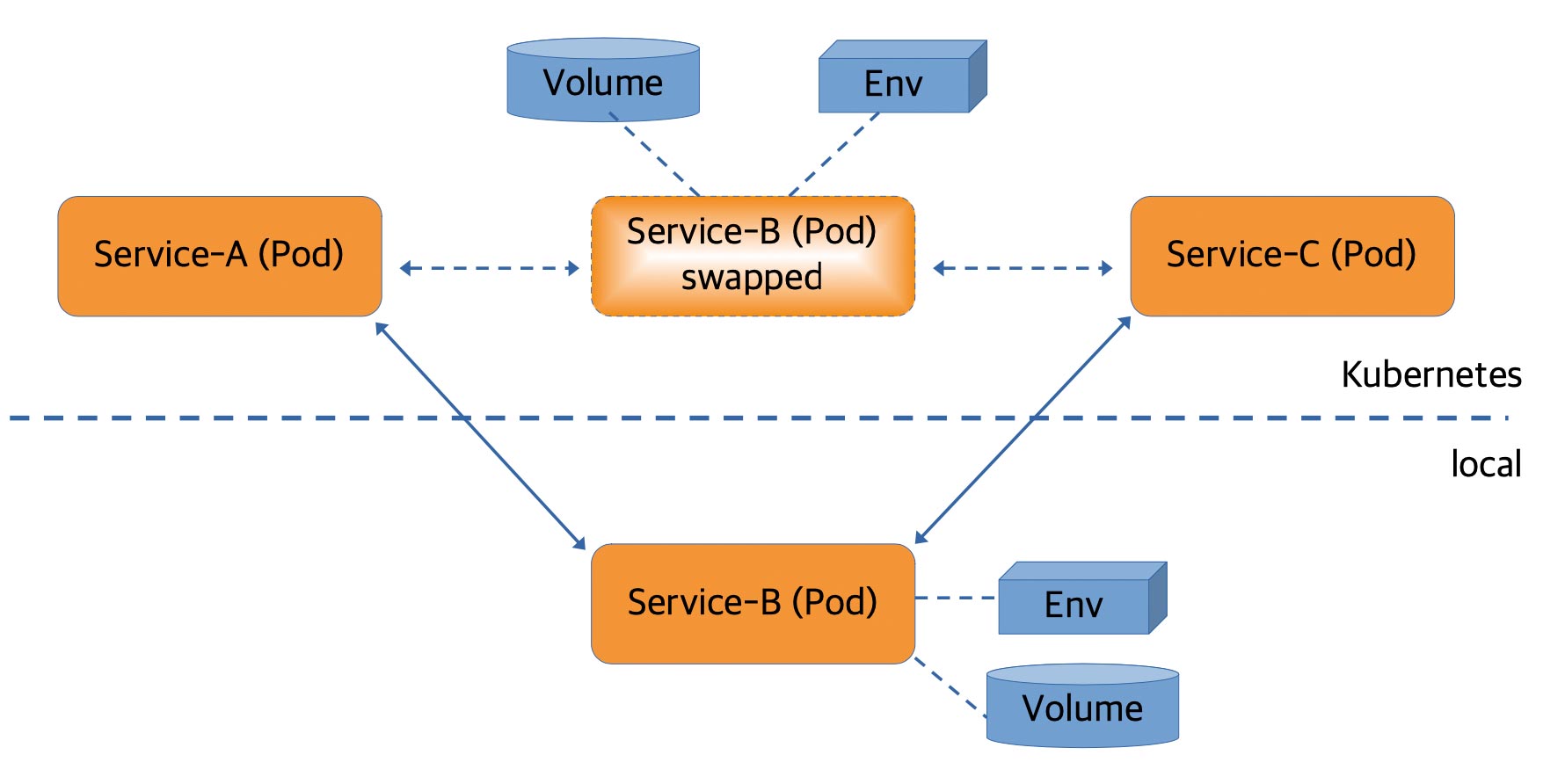
Fig. 2: Swap deployment
As an additional feature — aside from modifying the local network settings — the volumes and environment variables from the Kubernetes pod are also made available for the local environment. Telepresence [18] and the Visual Studio code plug-in Bridge to Kubernetes [19] are suitable tools for swap deployment.
Another consequence of this approach needs to be mentioned. Replacing the running pod with the proxy is transparent to all developers with access to the cluster. That is, when another developer sends a request to this (replaced) pod, it also ends up in their own local development environment. Meanwhile, both tools can compensate for this behaviour by running the proxy alongside the original pod. This way, requests from fellow developers are no longer routed to the local instance. Unfortunately, telepresence requires a commercial version of the tool to do this. Bridge to Kubernetes provides this in the open-source tool as well.
Local Kubernetes cluster
Normally, the Kubernetes clusters in the cloud, in the upstream stages, are based on the specifications required for the production stage. This means that the cloud clusters for the different stages are equipped with access restrictions (RBAC, security constraints) and have a network provider that controls the network accesses within the cluster. Other restrictions have also been carried over from the production stage.
“Just trying something out quickly” is difficult on such systems. Local Kubernetes clusters started on the developer’s computer are far more suitable for this. The developer has full access to this local Kubernetes and can easily try out a few things. Understanding how the Kubernetes cluster works behind the scenes is much easier now. Furthermore, skipping the CI/CD server for deployment can make the developer roundtrip faster. Provided you followed the advice from earlier in the article for the CI/CD part (use identical tools for CI/CD if possible). This is not to say that development should be limited to the local cluster, because the application must eventually be able to run on the productive stage in the cloud.
Local Kubernetes clusters are possible with Minikube [20], DockerDesktop [21], or Kind [22], to name a few. Meanwhile, there are quite a few more such clusters, some with specialisation for specific purposes. Your own Internet research will undoubtedly be beneficial in this case.
Branch deployment
The connection of GitOps with the cloud and the new CI/CD servers now allows for so-called branch deployment. Build pipelines can be used to deploy a personal Git branch in the cloud without colliding with the actual deployment from the main branch. This allows a developer to test his changes in the cloud without interfering with other colleagues. The trick here is to dynamically create a private Kubernetes namespace that is only used for the selected Git branch. Individual tests can be done here, and when they are completed, the temporary artefacts should be cleaned up automatically. When merging the private branch, the pipeline should also remove the associated private Kubernetes namespace.
STAY TUNED
Learn more about DevOpsCon
In conclusion
This small overview of the Dev(Ops) Experience can only demonstrate how broad the topic is. In comparison to previous developments, the complexity has skyrocketed, as have the demands on development teams. Existing or newly-formed (DevOps) teams must manage a multitude of new subtasks. The transition from traditional development to the cloud is often accompanied by a steep learning curve for development teams.
The switch to cloud development cannot succeed without the right tools. It is therefore not surprising that there has been a veritable explosion of tools in this area in recent years. From where we stand today, the transformation is far from complete.
In many cases, the use of new tools is required, leaving no stone unturned. Often, a completely new toolchain is created that must work in tandem and even deal with the replacement of individual components.
All of this adds up to a completely new Dev(Ops) experience for us, with new opportunities as well as new challenges. Whatever the case may be. In any case, it’s still exciting.
Links and references
[1] https://helm.sh
[8] https://github.com/fabric8io/docker-maven-plugin
[9] https://github.com/GoogleContainerTools/jib/tree/master/jib-maven-plugin
[10] https://github.com/palantir/gradle-docker
[11] https://github.com/bmuschko/gradle-docker-plugin
[12] https://github.com/GoogleContainerTools/jib/tree/master/jib-gradle-plugin
[13] https://docs.docker.com/develop/develop-images/build_enhancements/
[14] https://github.com/GoogleContainerTools/kaniko
[15] https://buildah.io
[16] https://skaffold.dev
[17] https://github.com/ksync/ksync
[18] https://www.telepresence.io
[19] https://docs.microsoft.com/en-us/visualstudio/bridge/overview-bridge-to-kubernetes
[20] https://minikube.sigs.k8s.io/docs/start/





