


STAY TUNED
Learn more about DevOpsCon
According to the CNCF Annual Survey 2022 [1], hosting Kubernetes clusters in the cloud outweighs traditional on-premise hosting. For example, pure hosting in on-premise environments is now only 15-22 percent and larger organizations (> 1,000 employees) in particular. A majority (almost 63 percent), are at least taking a hybrid approach or are fully in the cloud. This broad adoption confirms how tightly Kubernetes is already dovetailed as a service in the cloud with the actual cloud infrastructure. Here are a few examples:
- Kubernetes nodes host on managed/unmanaged cloud VMs.
- Containers communicate with other cloud services through service accounts or stored cloud keys.
- Users and service accounts enable external access to the cluster infrastructure.
- Cloud consoles and CLIs enable provisioning and configuration of entire clusters.
- VPC peerings enable cross communication between VPC and its cloud services, like clusters.
However, this symbiosis also includes risks that an insecure Kubernetes cluster of an inadequately protected cloud can have on each other. These should not be underestimated. For example, unauthorized access to Kubernetes can lead to data loss, resource theft, and service outages within the cluster, and can potentially compromise the entire cloud environment. An example of this are cloud keys, which are often found on containers. The Wiz-Threat research team estimates that nearly 40 percent of all Kubernetes environments studied contain at least one pod with a long-term cloud key or associated IAM/AAD cloud identity [2].
Although hacker groups like TeamTNT specialize in spying on cloud identities in Kubernetes, this reciprocal relationship isn’t considered in security. Siloed views still dominate, both in the organizational structure, responsibilities, and technical specifications like CIS benchmarks for Kubernetes, AWS, Azure, or GCP. An exception is the MITRE ATT&CK for Kubernetes, which addresses possible attack tactics from Kubernetes to the cloud. But even this framework gives little indication of how easy these compromises can be [3].
Kubernetes Training (German only)
Entdecke die Kubernetes Trainings für Einsteiger und Fortgeschrittene mit DevOps-Profi Erkan Yanar
Kubernetes-to-Cloud vs. Cloud-to-Kubernetes
Before we look at two specific examples, first, it’s important to understand the two risk categories: Kubernetes-to-cloud and cloud-to-Kubernetes (Fig. 1).
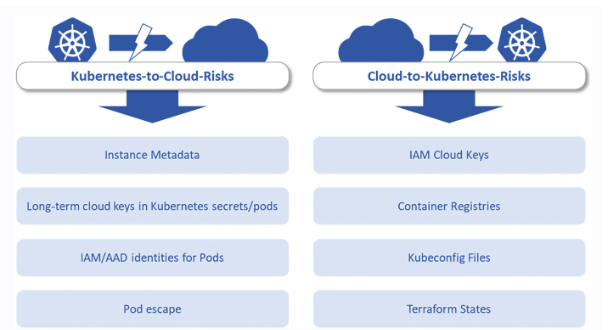
Fig. 1: Comparing Kubernetes-to-Cloud and Cloud-to-Kubernetes risks
Kubernetes-to-cloud risks address potential lateral movement scenarios that allow the attacker to break out of the Kubernetes cluster into the underlying cloud infrastructure. This category includes four common tactics [2]:
- Misuse of the worker nodes’ instance metadata IAM/AAD identities: Managed Kubernetes services assign a predefined role or service account to each worker node in a cluster. The kubelet daemon on the worker node needs these to make calls to the cloud service provider API (auto-scaling). Therefore, the worker node can also query its instance metadata via the IMDS (Instance Meta Data Service) endpoint. This endpoint is usually located at the local IPv4 address 169.254.169.254, so an attacker is able to take over the predefined role of the worker node when there is a compromise. The impact of a compromise differs from cloud provider to cloud provider. At AWS, the worker node is given three policies by default (AmazonEKSWorker-NodePolicy, AmazonEC2ContainerRegistryReadOnly, AmazonEKS_CNI_Policy), ranging from listing sensitive resource configurations to shutting down the cluster, to full read access of the associated container registries and their stored images. GKE, which we’ll look at in more detail later, also has an overprivileged default role that gives access to sensitive resources and deletion of entire compute instances in the cluster. Only AKS provides a secure default configuration. This first ensures that all cluster resources communicate with the control plane via a provider-managed identity that an attacker cannot access. This restriction depends on the user adhering to the default configuration and not granting additional privileges to the worker node via its system-assigned or user-assigned identity.
- Storing cloud keys in Kubernetes objects allows attackers to access other cloud resources undetected. Long-lived cloud keys (e.g. Azure Service Principals, IAM Secrets) are stored in Kubernetes Secrets or directly in the container image. This allows pods to perform operations on the cloud environment at runtime. Good examples of this are containerized backend tasks or CI/CD tools responsible for provisioning other resources. What’s especially problematic about this approach to identity assignment is that keys are often generated with unlimited lifetimes. Users like to associate their own over-privileged rights with the key. Under certain circumstances, this can lead to an immediate takeover of the entire environment.
- Misuse of pod IAM/AAD identities is risky when cloud IAM/AAD identities are directly assigned to Kubernetes pods and their service accounts. IAM roles for service accounts are a good alternative to locally stored cloud keys since they are bound to the container. But if there is a compromise, they allow the attacker to directly access the credentials of the service account and thus, they can laterally penetrate the cloud context. Therefore, these identities should always be assigned using a least privilege approach.
- Exploitation of (traditional) pod escapes that can extend into the cloud environment: An attacker breaking out from a pod through critical misconfigurations or vulnerabilities can reach the underlying host and potentially access other pods running on it.
This Kubernetes Lateral Movement can then access other pods with IAM/AAD identities or cloud keys. The Pod Escape’s impact on the underlying host can also be affected by the RBAC permissions assigned to the Kubelet. All Managed Kubernetes providers would at least allow full read access to all cluster resources with the Kubernetes REST APIs (URL/api/*). In AKS, write access to critical Kubernetes objects like create/delete pods or even update nodes is added. The attacker could also launch a malicious pod and assign it a Kubernetes service account with AAD user-managed identity. This can be hijacked and compromised, as we described above. A detailed list of attack possibilities per cloud provider can be found on Wiz’s blog post at [2].
Kubernetes owners shouldn’t underestimate the reverse case either. While previous tactics focus on instances where an attacker is already on the cluster and breaks out into the cloud, the reverse is also possible. Cloud-to-Kubernetes risks are potential lateral movement scenarios that allow the attacker to take over entire Kubernetes clusters from cloud resources [4]:
- Misuse of cloud keys with access to the Kubernetes cluster: Cloud keys can be found almost everywhere in the cloud environment, on local machines of developers and in CI/CD pipelines. As previously discussed, cloud keys enable authentication and authorization in the cloud environment for both technical and regular users. Cloud environments follow the security paradigm: “Identity is the new Perimeter”, since no network restrictions apply to this type of access. The impact of an attack using the identity vector depends primarily on privileges. Nevertheless, it’s important to understand how the key material differs between cloud providers:
- AWS IAM Keys: These are primarily user access keys. By default, the EKS cluster’s creator receives the system:master rights that would allow him to administer the EKS control plane. Other IAM identities must first be assigned these rights manually.
- GCP cloud keys: Cloud keys in GCP enable the creation of Kubeconfig files and authentication to GKE clusters in the tenant. The cloud key controls access to the GCP project, while the cluster RBAC is still responsible for access in the cluster. Project admins have full access to the entire cluster.
- Azure keys: Azure keys behave similarly to GCP cloud keys and, by default, allow AAD users to create Kubeconfig files (Local Account with Kubernetes RBAC). Since AKS clusters are not connected to Azure Active Directory (AAD) by default, users receive a client certificate with the Common Name (CN) master client and the associated system:master group. This means that a compromised AAD Identity only needs the minimal privileges to list cluster user credentials to generate a Kubeconfig file and gain full AKS cluster admin access [5]. Since this configuration is very risky, Azure offers two possible alternatives: AAD Authentication with Kubernetes RBAC and Authentication with Azure RBAC. Both ensure that AAD handles all rights management and any initial API call to the cluster API requires authentication over the browser first. Cloud keys in these variants aren’t dangerous until they have been granted the appropriate rights via AAD.
- Compromising the cluster via container images from the container registry: By default, cloud users often use a cloud-based container registry (AWS: ECR, Google: GCR, Azure: ACR) in addition to managed Kubernetes services. In the event of a container registry misconfiguration, attackers can gain access to repositories through both the identity and network vectors. Besides poaching images in search of key material, push privileges can also be used to execute supply chain attacks. For example, the attacker can build a backdoor into an existing container image and push it to a trusted repository with the same name and tag. If the image is deployed to the cluster, it lets the attacker directly enter the cluster environment.
- Misuse of kubeconfig files to penetrate the cluster: Development machines and CI/CD tools often store a Kubeconfig file locally (default path: ~/.kube/config) to authenticate against the cluster. As already described in the previous cloud keys scenario, besides unmanaged Kubernetes clusters, AKS clusters with default configuration are susceptible to this type of attack since they don’t require access to the AAD identity or an associated cloud key.
- Misuse of compromised Terraform state files: Kubernetes clusters are often also defined and provisioned with In-frastructure as Code. After successful provisioning with Terraform, the associated state is stored in a location. The most secure variant is most likely in the Terraform cloud. However, this comes at a cost so many teams choose to store the state files in a shared location, such as a bucket. Because terraform state files also contain the key material for authentication to the cluster, compromising terraform state can lead to direct takeover of cluster resources.
Attack on IMDS metadata
Now that we have a general overview of possible Kubernetes-to-Cloud and Cloud-to-Kubernetes risks, it’s time to take a closer look at real-world examples from a technical perspective. Let’s start with the first Kubernetes-to-cloud scenario: “Misuse of instance metadata IAM/AAD identities of worker nodes.” Although this example may sound complex, implementation is shockingly simple.
For our example, we first chose GCP as the cloud provider and assume the following setup:
- GCP Project Names: wizdemo
- 1 Standard GKE Cluster (not auto-pilot):
- Kubernetes Version: 1.25.8-gke.500
- Name: entwicklermagazin-demo
- Number of Worker Nodes: 2
- Region: us-central1
- Private Cluster: disabled (publically available)
- Network and Subnet: default
- Other Configurations: default
- 1 Bucket:
- Public Bucket: not Private Bucket
- Region: us-central1
- Contents:
- file1.txt: This is a file containing secret data from a bucket
- file2.txt: This is a file containing more secret data from a bucket
- file3.txt: This is a file containing more secret data from a bucket
Initially, a simple container runs on the GKE cluster. This contains only an alpine:latest base image and the packages curl, wget and jq. A simple curl or wget command is enough to contact the metadata service. The jq command only aids for later visualization (Listing 1).
Listing 1:

For simplicity, we choose a default pod as the deployment method. The pod is deployed into the default namespace. Since we don’t need to change its Kubernetes permissions, it’s assigned the default Kubernetes service account [5] (Listing 2).
Listing 2:

Now, let’s assume an attacker managed to access the pod’s command line. In practice, this can happen for a number of reasons. Three examples:
- Vulnerability exploitation: The pod is exposed by a service to the Internet and an application running on it lets the attacker execute arbitrary code through a vulnerability or directly build a reverse shell.
- Supply chain attack: The attacker injects a reverse shell using a malicious container and performs a supply chain attack into a malicious container (see also Cloud-to-Kubernetes risk number 2).
- Insider attack: An attacker already has access to the Kubernetes API and gets to the container using kubectl exec.
On the container, as seen in Listing 3, we launch our curl requests to the IMDS endpoint of the underlying worker node (IPv4 address 169.254.169.254).
Listing 3:

Once inside the container, we’re interested in two pieces of metadata in particular. The Google Project where the cluster was deployed and the service account’s access token the worker node needs for execution. By default, GKE assigns an overprivileged service account with the roles/editor role to worker nodes [7]. But this would also mean actively switching to user-managed service accounts by default. Even GKE’s recommended roles/container.nodeServiceAccount role with minimum privileges still gets useful privileges like storage.objects.list or storage.objects.get [8].
Using the project ID and access token, we’re able to access cloud resources outside the cluster. Google’s REST API serves us here. First, we list all buckets within the project with the endpoint https://storage.googleapis.com/ (Listing 4).
Listing 4:
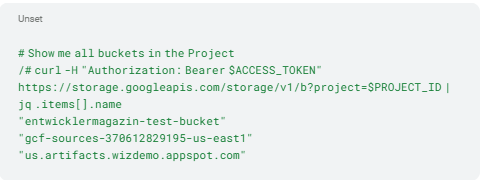
We’ve already find our target: the entwicklermagazin-test-bucket next to gcf-sources-370612829195-us-east1 (a bucket for build logs) and us.artifacts.wizdemo.appspot.com (a bucket for staging files). Last but not least, we just need to read the objects and exfiltrate them to a desired location. In our example, we store the first file locally in the container and read them out (Listing 5).
Listing 5:

To simulate the attack, we only used curl and jq, so it would be easy for any attacker to transfer the steps into a simple shell script without installing specific Google Cloud assets like the gcloud CLI. The graphic in Figure 2 was created by the CNAPP solution Wiz directly from the Cloud and Kubernetes environment and summarizes our exact attack path.
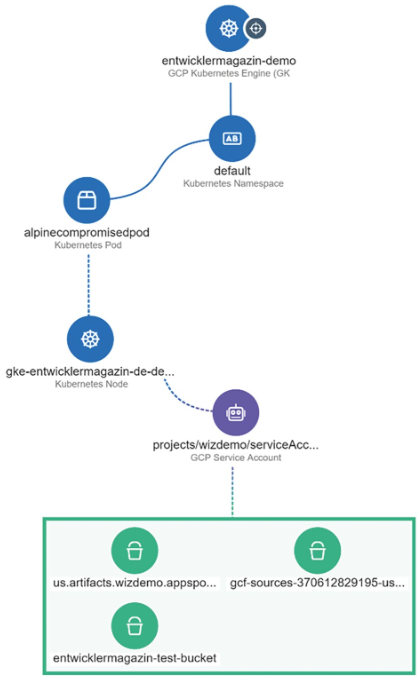
Fig. 2: Live attack path from IMDS metadata to cloud bucket
To reduce the risk of an attack, users have several options:
- Minimizing the default service account’s rights ensures that only essential services can be accessed. However, the alternative Metadata Concealment is no longer recommended and is deprecated [10].
- You can also consider blocking the IMDS via network policies. GKE allows the use of network policies (e.g., GlobalNetworkPolicy), which can be used to leverage egress rules to block traffic to 169.254.169.254 [11].
- If no standard cluster is required in GKE, the risk can be completely avoided using autopilot clusters that provide additional security features.
- Runtime security monitoring via e.g. eBPF-based sensors can be used to detect and block potential attacks with the IMDS service.
Terraform state files as an entry gate to the cluster
The second example shows a common cloud-to-Kubernetes risk: misuse of compromised Terraform state files. Internet Exposed Buckets are a fundamental challenge in all cloud environments and it repeatedly makes headlines (e.g., [12]). Unfortunately, it often results from unintentional misconfiguration. This is especially dangerous if it also involves buckets with configuration or log files. In the “State of the Cloud 2023” report, the Wiz-Threat research team publicly posted S3 buckets with well-known company names and the extensions -backup and _logs on the web. It took only 13 hours for external resources to place the first list attempts on the buckets. The time was nearly halved to 7 hours when S3 buckets with random names were simply referenced in GitHub repositories. One brief moment of carelessness quickly leads to far-reaching consequences, all the way into the Kubernetes cluster.
For our second example, we chose AWS as the cloud provider and build on the following setup:
- 1 AWS Account
- 1 Standard EKS Cluster
- Kubernetes Version: v1.24.13-eks-0a21954
- Name: entwicklermag-demo-cluster
- Number of Worker Nodes: 2
- Region: us-central1
- API Server Endpoint Access: Public and private (publically available)
- Network and Subnet: default
- Other Configuration: default
- 1 Bucket:
- Public Bucket: not Private Bucket
- Region: us-central-1
- Contents: terraform.tfstate (Terraform-State-Datei)
As described in the previous section, the initial situation for this scenario is that the Terraform state file for an AWS cloud configuration is placed in a publicly accessible S3 storage bucket. Besides other cloud infrastructure configurations, the state file also contains the Kubernetes configuration, including the certificates required for administrative access. In the following, we’ll show how a potential attacker can use the Terraform state file to create a Kubernetes configuration file with little effort, gaining full access to the Kubernetes cluster.
Figure 3 illustrates the attack vector of the bucket exposed to the Internet to the public EKS cluster’s Terraform state file. Figure 4 lists the Kubernetes certificates stored in the bucket as an example from the CNAPP solution Wiz.
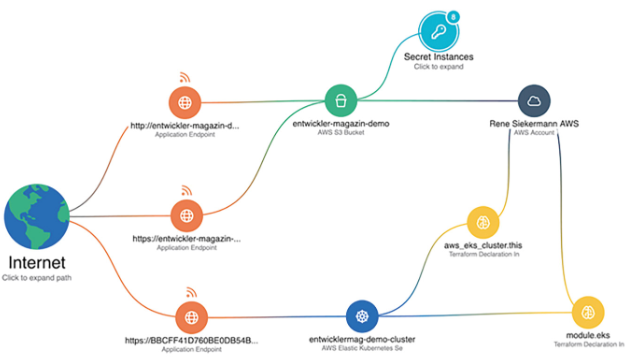
Fig. 3: Correlation of the running EKS cluster with the terraform state information.
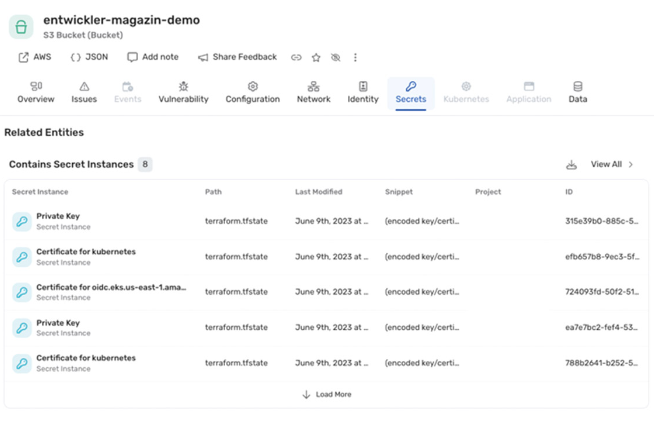
Fig. 4: Terraform state file with Kubernetes cluster certificates
A potential attacker can download the terraform-state file (terraform.tfstate) via the publicly accessible S3 bucket and get access to all the information needed to create the Kubernetes configuration file (~/.kube/config). This requires the three sections cluster, context, and users. The terraform.tfstate file listed in Listing 6 shows the relevant Kubernetes cluster information. The corresponding values are transferred to an empty .kube/config file (Listing 7).
Listing 6:

Listing 7:

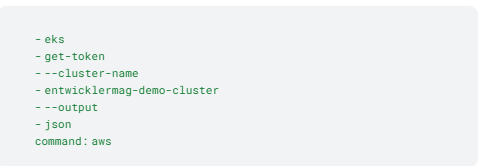
After the Kubernetes configuration file (~/.kube/config) is created, the attacker can use the kubectl command to connect to the Kubernetes cluster and get an initial overview of the cluster. Listing 8 shows an example of listing the individual nodes of the cluster, namespaces, and running pods in one of the namespaces (entwicklermagazin-demo).
Listing 8:

The attacker can still use kubectl auth can-i –list to find out which additional permissions they have in the cluster. For EKS, for example, the cluster’s creator is assigned the system:masters permissions by default [14]. These are linked to the clusteradmin role with role binding (Listing 9). The attacker has clusteradmin privileges. The situation is similar for GKE and AKS [4].
Listing 9:

They also allow easy shell access to pods to exfiltrate data, and create new resources to perform cryptojacking (Listing 10).
Listing 10:

These are just a few examples of possible attack scenarios. This also closes the first example’s circle. Starting from the Kubernetes cluster, the attacker can spread laterally to other cloud resources. To reduce the risk of this kind of attack, users have various options:
- For teams, a Terraform state file central repository makes sense in principle, so that they can work together on defining the cloud infrastructure. However, you should be aware of the associated risks and make sure that access is restricted as much as it can be. Access for AllUsers or AuthenticatedUsers in S3 should be avoided. Creating bucket policies for Access Control Lists (ACL) ensures that only selected principals are granted access to the bucket [15].
- Additionally, centrally created Terraform state files should be encrypted. Both the Terraform Cloud and AWS S3 offer this.
- Access to the Kubernetes API can also be restricted. In a departure from the demonstrated example, instead of a fully public API endpoint, you could use IP address whitelisting to restrict access to known IP ranges. [16]
Conclusion
Kubernetes and the cloud complement each other perfectly. However, the mutual dependency also comes with hidden risks that users often aren’t aware of. In order to arm yourself against attacks in the cloud and the cluster, you must consider the attack vendors and address them in an interdisciplinary way. Both hardening the cluster and sensible segmentation of cloud resources using identity and network are a must.
References
[1] https://www.cncf.io/reports/cncf-annual-survey-2022
[3] https://www.microsoft.com/en-us/security/blog/2020/04/02/attack-matrix-kubernetes/
[8] https://cloud.google.com/iam/docs/understanding-roles#kubernetes-engine-roles
[9] https://cloud.google.com/storage/docs/request-endpoints?hl=de
[10] https://cloud.google.com/kubernetes-engine/docs/how-to/protecting-cluster-metadata
[11] https://cloud.google.com/kubernetes-engine/docs/how-to/network-policy
[13] https://www.wiz.io/blog/the-top-cloud-security-threats-to-be-aware-of-in-2023
[14] https://docs.aws.amazon.com/eks/latest/userguide/add-user-role.html
[15] https://docs.aws.amazon.com/AmazonS3/latest/userguide/example-bucket-policies.html
[16] https://repost.aws/knowledge-center/eks-lock-api-access-IP-addresses“



