

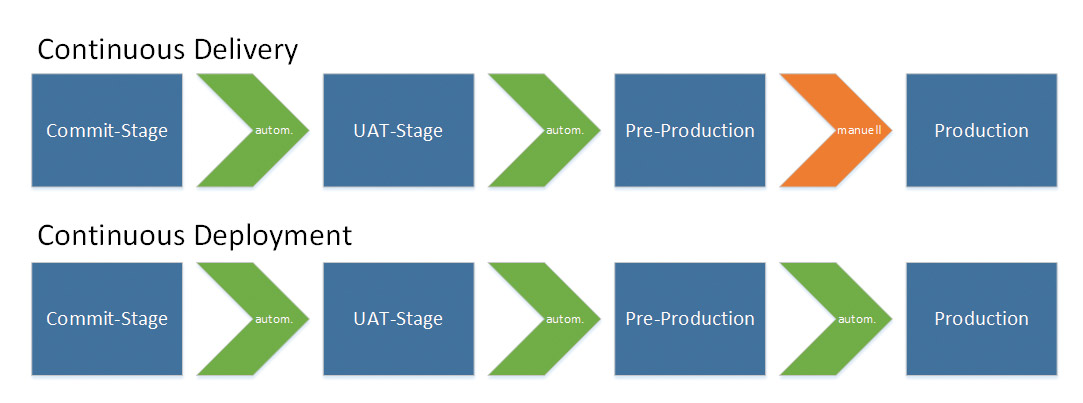
As far as Continuous Deployment is concerned, there are different views. One definition states that continuous delivery ends at a pre-production stage, so Continuous Deployment is the ability to generally deploy into production, regardless of whether this is done manually at the push of a button or automatically (Fig. 1).
According to an alternative definition, Continuous Delivery also includes manual deployment in production, but in Continuous Deployment, this deployment is always automatic.
In this article, we assume the second definition, so the question of what “manual at the push of a button” can mean doesn’t arise.
Step 1: Continuous Integration
Continuous Integration (CI) is a fundamental practice in (agile) software development. Due to shorter release and product cycles, it is imperative to continuously integrate the development with every commit. This ensures that the code can be compiled and functioning software can be delivered at any time – and any errors that occur are quickly reported back to the developers (Fast Feedback or Fail Fast). Automated tests and analyses help ensure continuously high-quality code and applications. Continuous Integration servers such as Jenkins play a decisive role in this.
The branching concept is just as important. Trunk-based, i.e., a central branch for all commits, has proven to be successful. Feature branches should be avoided as far as possible to prevent merge conflicts and enable Continuous Integration. Alternative techniques to enable longer-lasting changes are described in “Step 2a” and “Step 2b”.
In addition, checks should be performed for dependency vulnerabilities. In the best case, dynamic security tests (DAST) are also carried out to detect vulnerabilities in your application at an early stage.
STAY TUNED
Learn more about DevOpsCon
Step 2: Continuous Delivery
Continuous Delivery (CD) as an extension of CI pursues the goal of delivering smaller changes to software faster and more frequently. This reduces the risk associated with large releases and increases confidence in the company’s ability to deliver.
The same requirements apply for CD as for CI, i.e., alternatives for longer-lasting changes must be introduced and automated tests must exist. Scripts may be required for automated deployment, depending on the technology and infrastructure used. Furthermore, automation of database changes plays an important role. Tools exist for this purpose, such as Flyway, which also claim zero downtime for schema changes through concepts such as two-phase migrations.
A prerequisite for CD is the development of a delivery pipeline. Which tool is used for this depends on your preferences and the condition of other frameworks. Regardless, it is essential to have a scripted pipeline, which is versioned with the project, enabling reproducibility. If development must support a large number of systems, uniformity is equally important (Unified Deployment). Last but not least, CD deployment can bring organizational and cultural challenges that are much more difficult to overcome than technical ones. But these will not be considered further in this article, as that is beyond our scope.
Step 2a: Branch by Abstraction
Branch by Abstraction concerns development or application preparation and pursues the goal of being able to make incremental changes to an existing system while maintaining deliverability. This method is applicable if the team is already familiar with trunk-based development. For changes to existing functionalities, an abstraction layer is developed that acts between the old and new implementation. This means that unfinished implementation statuses can simply be continuously delivered as Dark Deployments. Often, these changes involve cross-functional issues such as performance, framework replacements, or major refactorings. Real tests can be carried out with the help of a reverse proxy that forwards part of the requests to the new implementation in the background (Shadow Traffic). Alternatively, it’s also possible to route all live traffic to both the previous and new implementation.
This approach is also known as parallel change or change by abstraction (refactoring) and works best in combination with feature toggles, which can be used to switch between old and new implementations. Detailed information on the process of using this method is available.
Step 2a: Branch by Abstraction
Feature toggles are a technique for decoupling a deployment from a release and are an alternative to feature branches. This technique speeds up development by eliminating the need for branches and merges. It allows many small incremental software versions to be deployed by allowing developers to hide new or incomplete features so they do not appear in the user interface. Some call this in-code branching.
There are frameworks such as togglz that offer a convenient user interface to manage, activate, or deactivate all switches – combined with a special release strategy. It is possible to deploy a function to only a few users, e.g., selected by name, IP address, location, or incrementally with a few percentages (see also Canary Deployment). This approach can be used to perform A/B testing, which means that a feature is enabled only for a subset of users to try out in order to see if the change is accepted. If a feature causes errors or simply doesn’t work as it should, the switch is disabled and developers can work on a new increment for deployment. Such behavior is called fix forward and means that there is no need for rollbacks. This can save a lot of time since it can be a lot of work to prepare database scripts to allow rolling back to the previous version. Finally, function switches can be used to put an application into maintenance mode.
Developers must enclose the entry point of a feature with an if-else construct in their code (Listing 1).
if (Features.ENABLE_IMPORT.isActive()) {
LOG.info("IMPORT started");
try {
Future<Boolean> future = importService.holeDataFromOnlineApplication();
...
} else {
LOG.info("IMPORT not possible");
}
An example of how a pie chart is rendered on a dashboard via toggle in JSF is shown below:
<div class="Container50 Responsive50">
<p:chart rendered="#{features['SHOW_TASKS']}" id="pieOperationstatus" type="pie"
model="#{dashboardBean.pieOperationstatus}" responsive="true" />
</div>
A code block that has been turned off by switch is comparable to commented-out code.
It is important to take care to remove the toggles after they are no longer needed, otherwise, it will result in dead code, leading to new technical debt. Feature toggles can be stored in a database or as a property in a configuration file.
Step 3: Zero Downtime
The following practices are release strategies and pursue the goal of enabling deployments without downtime.
Step 3a: Blue-Green Deployment
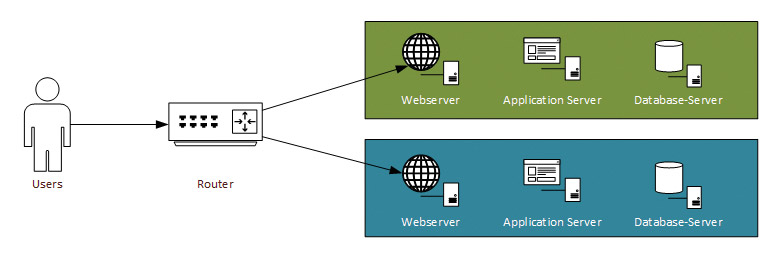
Blue-Green Deployment (Fig. 2) is a release practice that switches between two production environments called blue and green. On a second environment, a new software version is installed and tested without the users noticing. If the new version has been tested successfully, the router can be reconfigured so that all requests are forwarded to the environment with the new software version. The first environment is removed from the routing. If something goes wrong, it is possible to switch to the green environment where the last stable version is running. The main goal of this approach is risk mitigation. It is usually an all-or-nothing release strategy for new versions.
The main challenge of this approach is the need to run two complete production environments, which can be very expensive in terms of cost and effort. This procedure is rather difficult and excessive for small changes, especially if they will be released several times per week or day. In this case, feature toggles may be sufficient. However, it can be useful to combine Blue-Green deployments with feature toggles to release major versions of an application. Finally, this is primarily a release strategy for IT operations, while feature toggles provide release control for development or the product owner.
Step 3b: Canary Deployment
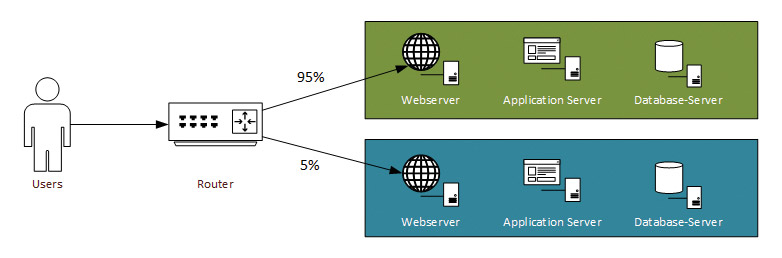
Canary Deployments (Fig. 3) can be used to deploy a new version of an application to a subset of users while monitoring behavior. If something goes wrong, those users can be redirected back to the old version. If the new changes work as expected, the changes are rolled out to the rest of the users.
The name of the strategy comes from the practice of using canaries in coal mines to detect carbon monoxide and other toxic gases before they endanger people.
This strategy can be implemented with load balancers by directing 95 percent of traffic to environment A and five percent to environment B. While an environment is being updated, it is taken out of rotation.
Similar to Blue-Green deployments, there is a need for duplicated infrastructure – the difference is that with Canary it is only temporarily. The new infrastructure must be deployed for the new version, while the old version’s infrastructure can be decommissioned after all traffic has been redirected to the new version.
Sometimes this approach is called a gradual or incremental rollout. In addition, it allows for A/B testing, where two different versions of a functionality are rolled out to see if version B generates higher click-through rates, longer time spent on the website, or even higher sales compared to version A. It may be necessary to use the parallel change approach to support multiple versions of the software in parallel, especially for database changes.
Step 4: Secrets Management
In a classic approach with shared responsibilities, the corresponding access data to productive databases, servers, or other systems is usually set manually by IT operations staff to the appropriate places in the configuration files before deployment. To take the path toward DevOps, the goal must be to hide access data – both from developers, who can now set applications productively and from system and database administrators due to increased security requirements.
For secrets management in dynamic infrastructures, there is excellent tool support such as Hashicorp Vault [5]. This is a digital key box written in Go with many other functionalities. In general, it is about secret storage and secure access to secrets. This can be the storage of key material and content encryption of sent and received data, confidential environment variables, certificates, database access data, or API Keys.
The secrets are retrieved via an API and the plaintext version never leaves the Vault. Access is only possible for authorized and authenticated users or applications, which is configured via policies. Every access to secrets is recorded (audit). The keys have limited validity and can be renewed automatically with so-called key rolling. For databases, dynamic secrets can be generated that are only valid for one access. If Vault is used to store the secrets of many systems, it becomes a critical system in terms of availability. Vault itself is operated with at least three instances and can use a Consul cluster as a backend to ensure high availability. Since version 1.4, Vault brings its own backend and removed this dependency, further simplifying operation and updates.
Using Vault addresses other known vulnerabilities, such as:
- Passwords that are rarely or never changed
- Manually rotating passwords and replacing them in hard-coded places
- Nobody knows who has access to what and when
- Certificates have a long lifetime
Vault offers other features such as Encryption as a Service, which performs encryption and decryption of data via the API so that the necessary keys never have to leave the vault.

Better Continuous Delivery with microservices
Explore the Continuous Delivery & Automation Track
Step 5: Security and compliance
The following practices aim to provide increased security for containerized applications or microservices architectures in an automated manner.
Step5a: Container security
Since systems can now go live continuously without any manual control, further security and compliance measures are required. Containers are usually used in dynamic or distributed infrastructures. It must be ensured that no unintentional foreign containers from unknown sources or manipulated images with malware make their way into production. Furthermore, no containers should be operated with images containing known vulnerabilities. Scanning container images for vulnerabilities is comparable to the procedure for third-party libraries in Java, which can be analyzed using the OWASP dependency check. With Clair, an equivalent open-source tool verifies container images against entries in the NIST database [7].
One compliance guideline should be to use only official or signed images. Official product images from vendors in Docker Hub are signed, such as images from NGINX, Couchbase, Redis, or alpine. However, with this policy, it’s required to sign one’s own images and unknown, downloaded, manually checked images too in order to signal their trusted, secure origin. This measure is called content trust and is supported by tools such as Docker Notary. A multiple key procedure enables authors such as developers or build systems to sign images. These authors, known as publishers, are then trusted.
Project Harbor is an open source cloud-native container registry that can be run on-premise and integrates vulnerability scans with Clair (or Trivy since 2.0) and content trust via Docker Notary. This simplifies operation considerably since all components (13 in total) are started in individual containers with the help of a single Docker Compose file. A convenient user interface can be used to prevent images from being pulled that contain vulnerabilities and/or are not signed.
In the context of a more comprehensive standard for container security, a registry with integrated vulnerability scan is only one building block, albeit a very important one. At OWASP, a Container Security Verification Standard (CSVS) with a total of 106 recommendations, divided into 12 categories and three levels each (beginner, advanced and expert), has been published in version 1.0. This standard is very well suited as a checklist for establishing proven security measures.
Step 5b: Inter-service Communication
In classic application landscapes, IP addresses and ports in firewalls could be enabled once. Load balancer configurations and routes in DNS were static. In cloud infrastructures, whether private, public, or on-premise, this static infrastructure becomes dynamic. Services are restarted with previously unknown IPs after a failure or due to scaling requirements at various locations.
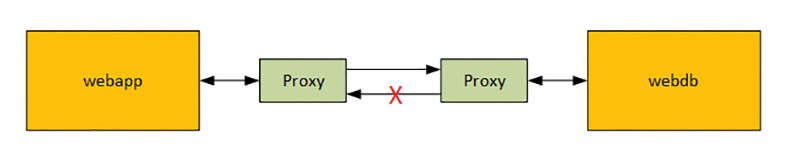
Manually changing firewall rules or load balancer settings as a result of a change request is no longer appropriate. The wait time would be too long and the frequency of changes too high. Due to the increasing number of services in a microservices architecture, the number of rules and routes also increases, which quickly leads to confusing and no longer maintainable sets of rules and configurations. In addition, the services also communicate with each other, so that east-west communication must be secured in addition to north-south communication. In a simple scenario (Fig. 4) consisting of two containers (with the web application running in the first container and a database in the second), it should be ensured that the container including the web application is allowed to communicate with the container in which the database is operated, but not vice versa.
HashiCorp Consul is already in use for service discovery and service configuration. It builds on this and since version 1.4, offers extended functionalities (Connect) to develop existing installations in the direction of Service Mesh. One of these functionalities is intention policies, which regulate that containers of the webapp group may access containers of the webdb group, but not vice versa (Fig. 4):
$ consul intention create -deny webdb webapp
Created: webdb => webapp (deny)
This is implemented with automatically-started Envoy containers that act as a service proxy.
These communication relationships can also be encrypted with Mutual TLS. The necessary certificates are issued automatically, either by Consul itself or, when connected to Vault, by the company’s own PKI stored there.
Final Destination: No Test Environments
If there is a desire to increase deployment speed, previously performed activities must be omitted, such as the installation and deployment of test environments. By introducing feature toggles, it is possible to deploy to production at any time, but the features are released later or only for a few test users. It may be necessary to maintain an environment for testing the deployment itself.
If explicit releases for features are still required, an alternative is to automatically start up new environments in which the respective feature is made available for acceptance. This achieves further independence and enables high release speed even in an environment where releases are still done manually.
Conclusion
In the roadmap presented in this article, we considered points relevant to introducing continuous Deployment to a company. For reasons of space, a description of further aspects such as Infrastructure as Code and the ability to provision necessary infrastructure automatically at any time, has been omitted. Additionally, other measures may be required in special operating environments.
Various continuous delivery maturity models already exist, which contain indications of one’s status and activities still to be performed.
Establishing continuous deployment in a grown organization is a challenge. In the end, you are rewarded with massively increased productivity and an enormous confidence boost in your product and supply chain. This leads to decreased risks, less stress, and more satisfaction for all project participants.
I wish you success on this exciting journey.



