
Intro
Nowadays, software has a profound impact on organizations, not only digital ones but also traditional ones, such as banks, insurance companies, and airlines. For example, most (if not all) banks today are digital. The importance of software means we must deploy and release more often, securely, and reproducibly.
If we take a look at the most common problems enterprises find when developing applications, they are:
- Slow and Risky Software Delivery: Traditional software development often involves long release cycles, with infrequent deployments that are risky and painful. The more content you deploy, the higher the chance of introducing a regression and identifying the cause of the problem.
- Siloed Teams and Poor Collaboration: Historically, developers and operations teams have worked in silos, leading to miscommunication, finger-pointing, and inefficiencies. Moreover, as complexity grows, the application requires more teams (security, testers, etc.) working on it, making collaboration between teams even more critical.
- Unreliable Software and Production Failures: Inconsistent environments and manual configurations frequently result in bugs in production. Manual deployments are the enemy of stability and reproducibility. Something that worked last time might not work this time because a human executed the process differently.
- Lack of Visibility and Slow Feedback Loops: Teams often don’t know how the software behaves in production until a customer complains.
- Difficulty Scaling Systems and Teams: As systems grow, managing deployments, environments, and team coordination becomes more challenging. In the past, applications were monolithic, relying on a single database; now, things are more complex, with multiple elements to manage.
So, with this complexity, we need methodologies to deploy correctly and adapt to the quickly changing world.
STAY TUNED
Learn more about DevOpsCon
STAY TUNED
Learn more about DevOpsCon
What is DevOps?
DevOps is about breaking down the wall between all the actors in a software development cycle (developers, testers, operations) to work together to build, test, deploy, and monitor software more efficiently and effectively.
- DevOps promotes continuous integration and delivery (CI/CD), enabling smaller, more frequent, and automated releases, thereby reducing risk and increasing speed.
- DevOps promotes a shared responsibility and collaboration culture through cross-functional teams and unified workflows.
- By utilizing Infrastructure as Code (IaC) and automated testing, DevOps ensures consistent environments across development and production.
- DevOps emphasizes monitoring, logging, and real-time feedback, helping teams detect issues early and respond quickly.
- DevOps practices support automation, standardization, and scalability, making it easier to manage growth efficiently.
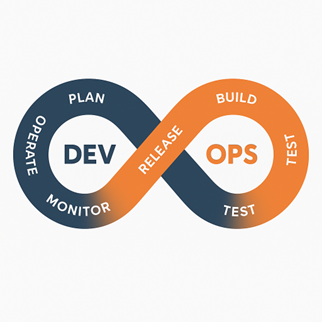
Fig. 1: The structure of the DevOps methodology
DevOps is a methodology that covers a broad spectrum of the software development lifecycle and implies a cultural shift in enterprises. However, in this article, we’ll focus only on the CI/CD part in a practical way.
DevOps is not a tool, but we ultimately need to rely on tools and specific implementations. Nowadays, GitOps is one of the most used DevOps practices for CI/CD.

Kubernetes Training (German only)
Entdecke die Kubernetes Trainings für Einsteiger und Fortgeschrittene mit DevOps-Profi Erkan Yanar
Kubernetes Training (German only)
Entdecke die Kubernetes Trainings für Einsteiger und Fortgeschrittene mit DevOps-Profi Erkan Yanar
What is GitOps?
GitOps uses Git as the single source of truth for infrastructure and application deployments, typically YAML files. You define elements such as a continuous integration pipeline, deployment files, and tools like Argo CD or Flux, which automatically apply the Git state to the actual infrastructure and continuously reconcile any drift.
The significant advantage of using GitOps is that all changes are tracked through Git workflows, including pull requests and reviews, which improves auditability and collaboration.
Git becomes a central piece in developing, building, and deploying processes; you need a Git server such as GitHub or GitLab and a project organization to store all the source code, the deployment manifests, scripts to build the project, or infrastructure files. There are several ways to organize a project to meet GitOps expectations, one of which is to use a single repository with multiple folders. For example, one folder can be dedicated to the application’s source code, another to deployment files, and a third to the build pipeline, and so on.
However, the best approach is to split the content into two repositories. One repository contains the application source code, and another contains all the manifests and scripts necessary to build, deploy, and release the application, as well as the manifests required to prepare the environment.
Figure 2 shows a real example of a project with two Git repositories: one containing the source code and another containing the manifests.
Fig. 2: Two Git repositories – one with the source code, one with the manifests
In this article, we’ll focus on the latter, which includes the pipeline definition for building the application, the Kubernetes files for deploying the application, and the reconciliation manifest (ArgoCD).
The repository layout can contain different folders:
- pipeline: In this folder, you’ll store all files related to building the application, typically YAML files for any CI/CD engine, such as Jenkins, GitHub Actions, GitLab Pipelines, or a native Kubernetes solution like Tekton.
- manifests: In this folder, you’ll store the files to deploy the applications. Nowadays, Kubernetes deployment files are standard, but they can also be other types, such as shell scripts or Ansible files.
- infrastructure: This is an optional folder for placing files related to the construction and configuration of the environment, such as the installation of Kubernetes Operators, Service Accounts, or Volumes, which are operations that you’ll run only once or rarely during the application’s lifecycle.
- continuous-delivery: Folder containing automation and reconciliation files using tools like ArgoCD, Flux, or Ansible Event-Driven, to automatically apply the Git state to the actual infrastructure and continuously reconcile any change in the Git files.
Of course, this may vary depending on the specific use case.
Let’s explore some examples in each of these categories.
Continuous Integration
The continuous integration pipeline defines the steps or stages that the system executes to obtain the application sources, compile them, run tests, create a delivery package (typically a container image), and push it to an artifact repository.
The following snippets show an example of YAML files defining these steps in Tekton (https://tekton.dev/).
Tekton is an open-source framework for building continuous integration/continuous delivery (CI/CD) systems on Kubernetes.
Clone Task
Kubernetes executes the clone task by instantiating a Pod with an Alpine container and executing the git clone command. It puts the cloned repository into a workpace so all other Tekton tasks can refer to these files.
apiVersion: tekton.dev/v1
kind: Task
metadata:
name: git-clone
spec:
params:
- name: url
type: string
- name: revision
type: string
default: "main"
workspaces:
- name: source
steps:
- name: clone
image: alpine/git
script: |
git clone $(params.url) --branch $(params.revision) $(workspaces.output.path)
Compile and Package
The other step is compiling, running the tests, and finally creating a package. For a Java project, it might look like:
apiVersion: tekton.dev/v1
kind: Task
metadata:
name: maven-build
spec:
workspaces:
- name: source
steps:
- name: mvn-package
image: maven:3.8.6-openjdk-17
workingDir: $(workspaces.source.path)
script: |
mvn clean package
Notice that the workingDir option refers to the workspace defined in the previous task.
Build and Push Container Image
The final step is to build a container image and push it to a container registry. Usually, there is no Docker Host in the Kubernetes installations to create a container image. You cannot run docker build because there is no Docker Host to execute it, but there are other ways to build a container using projects that require no Docker to build a container. There are several options, such as JiB, Kaniko, or Buildah (https://buildah.io/).
Here, we’ll use the latter one:
apiVersion: tekton.dev/v1
kind: Task
metadata:
name: buildah-push
spec:
params:
- name: image
type: string
workspaces:
- name: source
steps:
- name: build-push
image: quay.io/buildah/stable
securityContext:
privileged: true
script: |
buildah bud -f $(workspaces.source.path)/Dockerfile -t $(params.image) $(workspaces.source.path)
buildah push $(params.image)
Kubernetes starts the Buildah container and executes buildah bud for building the container and buildah push for pushing to the registry.
Pushing to an external registry requires a ServiceAccount with the container registry credentials configured via ServiceAccount secrets.
apiVersion: v1
kind: Secret
metadata:
name: container-registry-secret
type: kubernetes.io/dockerconfigjson
data:
.dockerconfigjson: <base64-encoded-auth-of-docker-config-object>
Create a service account and link it to this secret:
apiVersion: v1
kind: ServiceAccount
metadata:
name: build-bot
secrets:
- name: container-registry-secret
The last step is defining a pipeline to orchestrate all these tasks:
apiVersion: tekton.dev/v1
kind: Pipeline
metadata:
name: java-build-and-push
spec:
params:
- name: git-url
- name: git-revision
default: main
- name: image
workspaces:
- name: shared-workspace
tasks:
- name: clone
taskRef:
name: git-clone
params:
- name: url
value: $(params.git-url)
- name: revision
value: $(params.git-revision)
workspaces:
- name: source
workspace: shared-workspace
- name: build
taskRef:
name: maven-build
runAfter: [clone]
workspaces:
- name: source
workspace: shared-workspace
- name: image-build-push
taskRef:
name: buildah-push
runAfter: [build]
params:
- name: image
value: quay.io/myorg/myapp:1.0.0
workspaces:
- name: source
workspace: shared-workspace
Tekton is a big project, and the example will still require some consideration, but you now have an overview of Tekton and how to define a continuous integration pipeline using code.
Let’s jump to the manifest folder.
Manifests
In this folder, place the manifest files required to deploy the application in any environment. Depending on the environment and the application, you may need more or fewer manifests, but let’s keep things simple. An application deployed to Kubernetes that connects to a database requires two manifests: one for the database secrets and another for the application deployment.
apiVersion: v1
kind: Secret
metadata:
name: app-secret
type: Opaque
stringData:
DB_USER: myuser
DB_PASSWORD: mypassword
And the deployment file is injecting the secrets:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 1
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: my-app
image: quay.io/myorg/myapp:1.0.0
env:
- name: DB_USER
valueFrom:
secretKeyRef:
name: app-secret
key: DB_USER
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: app-secret
key: DB_PASSWORD
Applying these files using kubectl apply will deploy the application to Kubernetes, which is valid. However, GitOps also promotes the idea of automating and reconciling applications.
Continuous Delivery
One of the most important aspects of GitOps is the automation and reconciliation of the Git repository with the environment where the application is deployed. To implement this feature, you need an external tool such as Argo CD, Flux, or Ansible Event-Driven.
These tools implement the following four steps:
- Monitor the Git repository to detect any changes that may occur in any of the resources.
- Detect the drift of any resource or manifest placed there, usually a change in a Kubernetes manifest.
- Take action by applying the changed manifest to the Kubernetes cluster.
- Wait till the synchronization of the resources succeeds.
Any change in the system may be tracked through Git, and a process like Argo CD will detect the change and apply it.
For example, the previous Kubernetes deployment snippet deploys version 1.0.0 of the application (image: quay.io/myorg/myapp:1.0.0). After running the continuous integration pipeline to generate the 1.0.1 version, you may need to deploy this newer version. In GitOps, this is done by updating the deployment file container image tag to 1.0.1 (image: quay.io/myorg/myapp:1.0.1). When the change is committed and pushed to the repository, the GitOps tool detects the change and applies the manifest, triggering a rolling update from version 1.0.0 to 1.0.1.
The following figure summarizes the whole pipeline explained above.
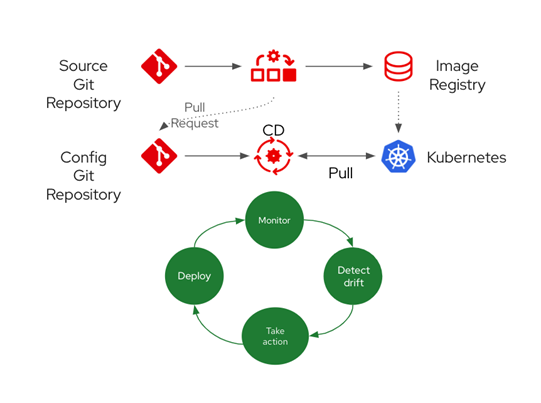
Fig. 3: Git pipeline
In the continuous-delivery directory, you’ll place the configuration file, in this example an Argo CD (https://argoproj.github.io/cd/ file, for reacting to any change made in the manifests directory of the Git repository:
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: myapp
namespace: argocd
spec:
destination:
namespace: myapp
server: https://kubernetes.default.svc
project: default
source:
path: manifests
repoURL: https://github.com/myorg/myapp-manifests
targetRevision: main
syncPolicy:
automated:
prune: true
selfHeal: false
syncOptions:
- CreateNamespace=true
Applying this manifest in a Kubernetes cluster with Argo CD installed will configure Argo CD to monitor the folder manifests of https://github.com/myorg/myapp-manifests repository.Any change made to this directory will trigger an update to the myapp namespace, applying the changed files.
We have the tools to implement GitOps, and we can see the significant advantages of having everything automated, from updating an application to recovering when something goes wrong.
But what about the database secrets defined in this example? They are in plain text in the YAML file, which means that anyone with access to the Git repository (even an attacker) can extract this sensitive data.
One option is to leave the Secrets outside of the GitOps workflow. It is an option, but it is never a good idea to have different workflows, as it creates two systems to maintain. To solve this problem, several projects are available to help you protect and store these files correctly. In this article, we’ll look at the Sealed Secrets project (https://github.com/bitnami-labs/sealed-secrets).
Secrets
Sealed Secrets is a Kubernetes project that enables secure management of Kubernetes Secrets in Git repositories, utilizing encryption to keep secrets safe within GitOps workflows.
How does it work? First, you need to install the Sealed Secrets controller in the Kubernetes cluster and the kubeseal CLI tool in your local machine (or the machine creating the secret).
In the local machine, create a standard Kubernetes Secret. For example:
apiVersion: v1
kind: Secret
metadata:
name: app-secret
type: Opaque
stringData:
DB_USER: myuser
DB_PASSWORD: mypassword
The controller generated a private and public key to encrypt and decrypt content during installation. Using kubeseal CLI tool, you’ll automatically get the public key from the cluster, and encrypt the Kubernetes Secret locally:
kubeseal --format=yaml < secret.yaml > sealedsecret.yaml
The output of the command is a new Kubernetes resource file of kind SealedSecret equivalent to a Kubernetes Secret, but encrypted.
apiVersion: bitnami.com/v1alpha1
kind: SealedSecret
metadata:
name: app-secret
namespace: myapp
spec:
encryptedData:
DB_USER: AgC2z9zN...truncated...== # base64-encrypted secret value
….
template:
metadata:
name: app-secret
namespace: myapp
type: Opaque
You can safely commit this file to the Git repository as its values are encrypted. You can also delete the original Kubernetes Secret as you don’t need it anymore.
When you manually or Argo CD automatically apply the SealedSecret object, the Sealed Secrets controller uses the private key to decrypt the object and recreate the Kubernetes Secret object inside the Kubernetes cluster for storage.
As you can see, you are protecting sensitive data from creation until the Kubernetes cluster consumes it.
Conclusion
In this article, we covered various technologies to implement GitOps effectively, including Tekton, Argo CD, and Sealed Secrets. Although they are widely used and battle-tested in large corporations, other solutions work perfectly well. What is important is to adopt a methodology that makes the process of building, deploying, and releasing an application safe, easy, and fast.
If you want to learn more about GitOps, you can download my book, GitOps Cookbook: Kubernetes Automation in Practice free from: https://developers.redhat.com/e-books/gitops-cookbook.







