

The landscape of building and deploying applications has long been too complex for one team alone to manage. With the advent of Continuous Delivery, all steps in the build and deployment process must be automated to allow speed and avoid errors. Plus, of course, each process step must be secure. Given the repeatable nature of the work, a number of highly successful open source and proprietary tools and languages have evolved in this space, allowing configuration of Infrastructure as Code and workflow specifications for build and deploy that automate repetitive steps such as testing. Each of these tools and languages is now a separate skillset in itself. This additional complexity created the need for a platform team who possess these skill sets and can create the deployment environment for application developers to use.
STAY TUNED
Learn more about DevOpsCon
STAY TUNED
Learn more about DevOpsCon
As platform engineering has evolved into an art form, the DevOps “one team” drive has somewhat dissolved again, as it’s very difficult to not only understand your own complex code base, but also its complex deployment process! This means that some of the hard work to remove the Dev/Ops boundary has fallen by the wayside. The cultural clash between Dev and Ops, whereby Dev need constant change, but Ops need stability, was resolved by getting the Dev teams to automate the Ops processes. But it has now become a clash between developers and platform engineering teams. The problems usually arise over access. The developer asks, “Why can’t I have access to my Docker logs?” It’s often the case that the two teams drift apart, don’t meet often enough, don’t work together, don’t collaborate in an Agile manner and as such, do not produce a fit-for-purpose developer platform.
Cloud native architectures
I want to examine the platform team versus developer team challenge in the context of modern cloud-native architectures. By “cloud native”, I am referring to architecture designed to be cloud-hosted, designed to run with maximum efficiency on a given cloud platform. And by “efficiency” I mean compute efficiency – which should in turn lead to cost efficiency. For example, if I build a scalable microservice architecture that will be hosted on Google Cloud Platform (GCP), I should not rent Linux boxes from Google and install my own Kubernetes instance on the boxes. Instead, I would evaluate serverless offerings, and if they weren’t sufficient, I’d rent Google’s Kubernetes engine (GKE) as a service and configure it to host my containers as needed. This allows Google to efficiently manage the underlying infrastructure as they see fit. Additionally, my dev and platform teams don’t need to know how to install, network, and configure Kubernetes onto bare tin. They only need to know how to customize it for their containers.

Kubernetes Training (German only)
Entdecke die Kubernetes Trainings für Einsteiger und Fortgeschrittene mit DevOps-Profi Erkan Yanar
Kubernetes Training (German only)
Entdecke die Kubernetes Trainings für Einsteiger und Fortgeschrittene mit DevOps-Profi Erkan Yanar
The same principle applies for peripheral applications used for observability. For example, logging. If I run my application on Azure, I can choose to use Azure application insights to consolidate, view, and search my logs instead of installing my own flavour of ELK stack.
This creates an interesting problem for platform engineers. A number of the areas they are used to controlling now belong to the cloud service. Skillsets such as Puppet, Chef, Ansible, NGINX, or Kerberos configuration for example, or tasks such as JIRA/Confluence/Git installation, ELK stack installation are no longer necessary. Complex tasks like creating VPNs and network routes become a simple drag-and-drop using a web interface that even developers can manage. The same is true for authentication, authorization, and role management. For testing and deploying serverless functions, I can just use AWS CodeDeploy via the GUI. You could argue that the development landscape niche that the concept of platform engineering expanded to fill no longer exists for cloud native development.
Control freaks
Let’s focus on a common platform engineering task: provisioning different environments for different users. Developers have a dev environment that they can release to at will. QAs want a QA environment that they can control versions in and that doesn’t fall apart mid-test. Users want a production-like environment where they can trial new features, and of course we need a live version. Plus, we need live-like environments to run load tests or penetration tests in. A decade or two ago, this would cause all sorts of pain and cost. For example, let’s say you have a Java app deployed as a WAR file to an application server. Installing the application server on load-balanced boxes, making sure it’s internet-accessible but secure and can communicate with the database used to be a highly skilled job. Each environment was created manually. There was the danger that human error would bring differences, and make the tests invalid. Even worse, application server licenses were WAY too expensive to be wasted on developers. You might have used Apache Tomcat for developers and Websphere for production. Then the applications the developers wrote wouldn’t run in other environments due to wonderful things like different versions of the Java SAX XML parsing library.
With the advent of scripting languages like Puppet, Chef, Ansible, and Terraform, it became possible to create an environment “stamp” that could be configured and re-used. This made the job of creating environments much more stable and allowed much more successful testing. However, particularly in the case of Puppet and Chef, the language paradigm was extremely unintuitive for functional or object-oriented developers. It was rare to get someone who could do both. Platform engineers ruled the world of scripting and provided ephemeral environments for everyone.
Jump forward to today and the concept of an environment in the cloud is nothing but a name. The only real difference between “test” and “production” is potentially the number of Kubernetes pods available for scaling, and the URIs the service talks to. Plus, the major hyperscalers provide some really nice GUIs and how-to guides. Take Microsoft Azure for example. Using their ARM templates platform, you can create a template from your development environment once you are happy with it, store the template in version control, and use it to “stamp out” as many copies of the environment as you wish – with provisions for configuration of both secure and less secure variables that change between environments. AWS CloudFormation is the Amazon equivalent.
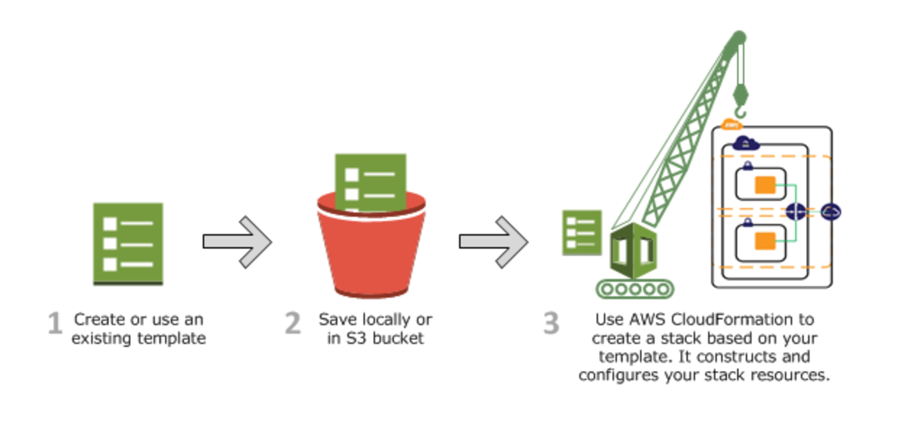
Figure 1: AWS CloudFormation for provisioning environments
This is no longer a skillset that a developer team can lack. If it’s the development team’s task to create the environments, it creates a sense of ownership for the running application. Yet, many platform engineers still consider environment provisioning to be their remit and theirs alone. This allows the barrier between devs and their deployments to stand. In this case, is the team really providing value? A self-service platform like backstage.io that gives developers access to the things they need creates a much better DevOps mindset. But, more on Backstage later.
The same principle applies with the build pipeline. If a platform engineering team creates the build pipeline but doesn’t give enough access to developers, the development team will go to all sorts of lengths to unblock themselves and get around it – with unpleasant consequences. A classic example is preventing developers from accessing their branch databases. I know a development team who dealt with this problem by deploying their own Postgres server onto Kubernetes pods and accessed the database through an illegal “dev” back door! That isn’t what you want in your environment.
A dead end?
Does this mean that we don’t need platform engineers anymore? Of course not! The “unicorn problem” still exists; it’s cognitive overload to try and understand both the application stack and deployment stack. Plus, there are a whole new set of security considerations to manage when hosting your environments in a public cloud. But it does mean that if we work with cloud platform providers, we can simplify the concept of a platform to “everything above Kubernetes”.
I have always been interested in how evolutionary concepts apply to all aspects of software engineering – from applications to architectures to ways of working. It’s not constantly necessary to change. For example, a lot of the Linux / UNIX kernel code is well over 40 years old and still going strong. Evolution simply means adapting to better fit your environment when your environment changes. Most companies need to evolve, as most companies’ operating landscape changes massively. A very small number of companies have thrived over time. According to research by McKinsey fewer than 10 percent of the non-financial S&P 500 companies in 1983 remained in the S&P 500 in 2013. That’s certainly where we are with the cloud native landscape. Hardware changes such as cheaper and better optic fibres, faster chips, longer living batteries, and 5G networks combined with software changes such as new security algorithms. This means that the cloud architectures have evolved, and as such, we need to move with it.
Now that the concept of the platform engineer has evolved, they need to evolve too and keep pace with the cloud native landscape. With the simplification of application provisioning due to improved tools, the biggest switch in this evolution is moving towards a customer mindset. The thing that the big cloud providers do well (and some do REALLY well) is making their developer services extremely customer-friendly, where the developer is the customer. Open source libraries and frameworks have also taken this step. I’ve already mentioned Backstage.io and how it really focuses on the developer experience. The move to self-service provisioning and away from a JIRA service-desk like approach to provisioning is a great help. For a modern, cloud-native platform engineering team to be successful, they need to treat the developer as a customer and work with them in an Agile way. This means focusing on user needs, researching the user experience, creating an MVP, and iteratively improving on it using customer feedback. These are things that come naturally to Agile development teams, but are rarer in platform engineering teams with their inherited operations-style background of being shut away in a locked server room, requiring stability and shying away from constant change. As a developer, I’ve never worked with a team like that. In fact, I’ve never worked with a platform engineering team. They tend to be in before development starts with a default set of requirements (“Create a pipeline, source code and artifact repositories, with minimal permissions”) and then they’re gone. Requests to change what’s in place tend to be via a service desk ticket with a multi-day SLA. It fills me with joy to think of having weekly sprint demos to show how our platform environment has improved in line with our requests!
Because DORA
A common question arises when discussing platforms to support development teams: Is investing in the developer experience worthwhile? Having the whole Agile team working constantly on non-business functionality sounds expensive, right? Devs are not the end of the chain. They should be working on improving the customer experience of the application users. So isn’t it just an unnecessary bottleneck in our team’s end goal to spend all this time focusing on whether or not our devs are happy? The DevOps Research and Assessment (DORA) is a long-running research program answering just that question. The outcomes are quite clear. If you want successful product delivery, you need a stable and successful pipeline. In other words, delays and security holes in getting software functionality to customers isn’t a Dev problem or an Ops problem. It’s a business problem. And as such, it has to be explained in business terms – which usually means giving it a monetary value.
This is possible, although there are so many variables that I will not attempt to give any sort of figures. The Google 2020 whitepaper “Return on Investment of DevOps Transformation” offers a way to calculate this by putting a number on unnecessary work saved and the retention of valuable skilled developers. The time saved can also be given a value in terms of new features that could be built using it.
Other metrics that can be given a value are security incidents (or lack of), and growth compared to competitors. The State of DevOps report can give ideas on the metrics to collect in order to figure out a value for missing security incidents, and to put a value on stability.
The final metric that is fairly easy to monetise and is tightly linked to a positive developer experience is attrition. Skilled developers are in high demand, and command top salaries. The industry expectation to replace a developer is approximately 6 months’ salary. Having an Agile, customer-focused platform engineering team that provides self-service Continuous Delivery functionality to the developers is a strong factor in whether or not a developer is satisfied in their job and likely to stay, with all the knowledge retention and cost saving this implies. Research shows that high-performing teams have up to 30% less attrition than those who do not focus on the developer experience.







