
Apache Cassandra was built to combine aspects of the Dynamo [1] and Big Table [2] papers and create a way to simplify how data could be read and written, so that it could then handle the volume of data that was being created. By keeping things simple, Cassandra reduced the complexity of read and write overhead and made it easier to scale and distribute data.
Storage Attached Indexing (SAI) is a new project to provide secondary indexing for Cassandra, while removing some of the problems with previous approaches. This should make it easier to query data held in Cassandra at scale, as well as reducing disk storage requirements per cluster.
The current approach to secondary indexes in Cassandra
As a distributed database, Cassandra can provide incredible scale, but it also requires some experience in how to model your data at the start. Database indexes then build on this initial data model to expand your queries and make them more efficient. However, that approach has to adapt over time. In order to keep up with new use cases and deployment models, we have to look at how Cassandra approaches data indexing, and then consider new ways to reduce that tradeoff between usability and stability.
The end goal for indexing is to improve how you read data. However, the decisions that you make at the start around how you write data will affect what you can do around indexing as well. If you are optimised for fast writes – as you are with Cassandra – added complexity can have a negative impact on how you manage indexing, and therefore affect your performance. It’s therefore worth looking at how data is written to a node within a Cassanda database cluster to start off (Fig. 1).
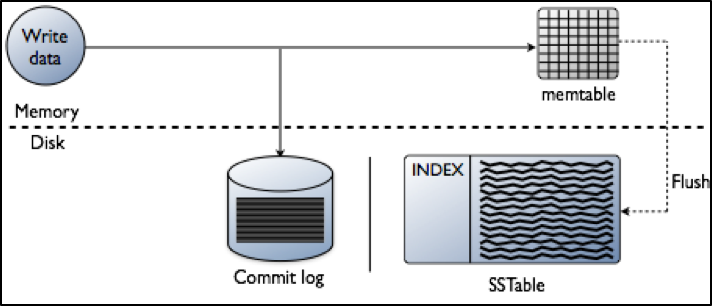
Fig. 1: Data processing in a Cassandra database cluster
Cassandra is based on a Log-Structured Merge (LSM) tree [3] approach where high insert volumes of data are expected. It’s a common approach and used by other databases like HBase, InfluxDB and RocksDB. By collecting writes and then providing them in pre-sorted runs of data, fast write speed can be maintained and the data organised for distribution. A transaction works like this:
- Each transaction will validate that data is in the correct format, and check against the existing schema.
- The transaction data will then be written into the tail of a commit log, putting it on the next spot on the file pointer.
- The data is then written into a memtable, which is a hashmap of the schema in memory.
Each transaction – called a mutation in Cassandra terminology – is acknowledged when those things happen. This is different to other databases that set a lock on a specific point and then seek to perform a write, which can take additional time to complete for each transaction.
The memtables are based on physical memory – as these fill up, the data in them is written out in a single pass on disk to a file called an SSTable (Sorted Strings Table). Once the SSTable holds this persistence data, the commit log is deleted and the process begins again. In Cassandra, SSTables are immutable. Over time, as more data is written, a background process called compaction merges and sorts SSTables into new ones which are also immutable.
Issues with previous indexing
The current approach that Cassandra has in place around data indexing has not kept up well with user requirements. For many users, the tradeoffs involved in implementing indexing as it currently stands were so onerous that they avoided using indexes at all. This has meant that many current Cassandra users use only basic data models and queries in order to get the best performance, and therefore miss out on some of the potential that exists within their data if they could model and index more effectively.
In the world of Cassandra, the partition key is a unique key that acts as the primary index, and is used to find the location of data within a Cassandra cluster. Cassandra uses the partition key to identify which node stores the required data, and then identifies the data file that stores the partition of data.
In a distributed system like Cassandra, the column values exist on each data node. Any query has to be sent to every node in the cluster, the data is searched, collected, and then it is merged. Once the result is merged, the result of that query is then returned to the user. In these circumstances, performance is down to how fast each node can find the column value and return that information.
Cassandra has two secondary indexing implementations: Storage Attached Secondary Indexing (SASI) and Secondary Indexes. While these implementations work for their specific use cases, they are not fit for everything. The two main concerns we have constantly dealt with as a project are write amplification and index size on disk. Understanding these pain points is important for understanding why we need a new scheme.
Secondary Indexes started out as a convenience feature for early data models that used Thrift. Thrift was then replaced by Cassandra Query Language (CQL) and the Secondary Index functionality was retained with the “CREATE INDEX” syntax. While this made it possible to create a secondary index, it also led to write-amplification by adding a new step into the transaction path. When a mutation on an indexed column took place, this would trigger an indexing operation that re-indexes data in a separate index file.
This would in turn dramatically increase disk activity in a single row write operation. When a node is taking a high amount of mutations – and this is what Cassandra was built to do – this can quickly lead to disks getting saturated and then affecting the overall cluster. It also makes planning ahead on disk space harder, as growth in data would be less predictable.
The other approach is Storage Attached Secondary Indexing (SASI). SASI was originally designed to solve a specific query problem and not the general problem of secondary indexes. It did this by finding rows based on partial data matching. Wildcard, or LIKE queries, or ranging queries on sparse data like timestamps.
SASI looked at mutations that are presented to a Cassandra node, and the data would be indexed in-memory during the initial write much like how memtables are used. This meant that no disk activity is required for each mutation, which is a huge improvement for clusters with a lot of write activity. When memtables are flushed to SSTables, the corresponding index for the data is flushed as well. When compaction occurs, data is reindexed and written to a new file as new SSTables are created. From a disk activity standpoint, this was a major improvement.
The problem with SASI is that these additional indexes required a large volume of disk storage to cover each column indexed. For those managing Cassandra clusters, this was a big headache. SASI was also something put together by one team and released with not much further improvement. As and when bugs were found in SASI, the fixes have been expensive.
Storage Attached Indexing and secondary indexes
To improve secondary indexing in Cassandra requires a new approach based on the lessons that have been learned from previous implementations. Storage Attached Indexing (SAI) is a new project that addresses the issues of write-amplification and index file size, while also making it easier to create and run more complex queries.
SASI had the right approach in using in-memory indexing and flushing indexes with SSTables. SAI therefore indexes data when a mutation is fully committed. With optimizations and a lot of testing, the impact on write performance has vastly improved. This should therefore provide a 40 percent increase in throughput and over 200 percent better write latencies compared to the previous Secondary Indexing approach.
SAI also uses two different types of indexing schemes based on the data type to deal with the issue of disk storage volumes. The first is to use Trie [4] based indexing for text, which uses inverted indexes and terms broken into dictionaries. This offers better compression rates and therefore smaller index sixes. For numeric values, SAI uses an approach based on block kd-trees [5] taken from Lucene to improve range query performance with a separate row ID list to optimise around token order queries.
By just looking at index storage, there is a big improvement in the volume versus the number of table indexes. To compare Secondary Indexing, SASI and SAI, we carried out some benchmarking to show performance levels against disk storage. As you can see in figure 2 the volume of disk used for SASI goes up massively as you expand your index data.
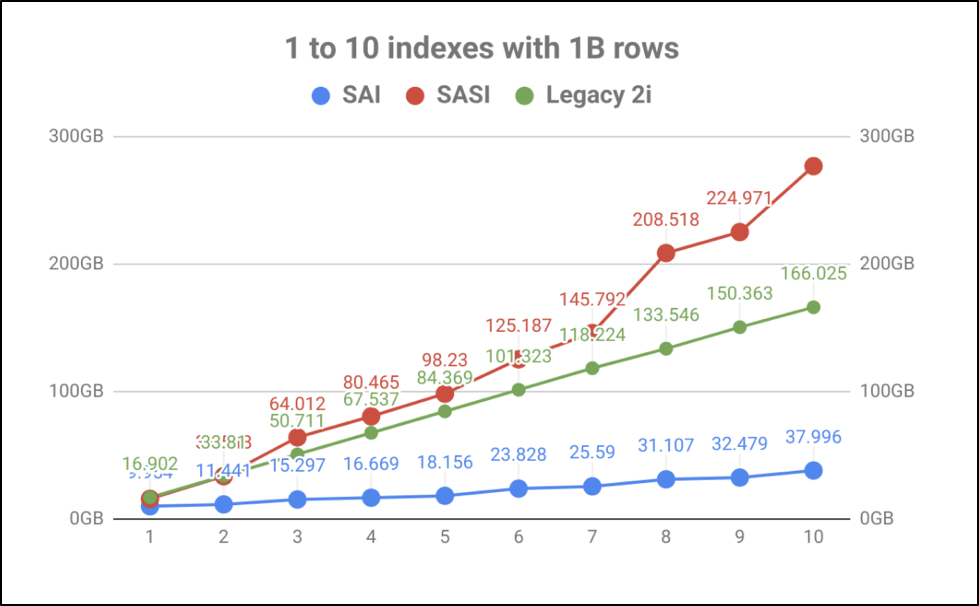
Fig. 2: Comparison of SAI, SASI and Legacy 2i approaches
Outside of write amplification and index size, SAI can also be expanded further in the future in line with the Cassandra project goals of more modular development in future builds. SAI is now listed as a Cassandra Enhancement Process as CEP-7 [6], and the discussion is on how it could potentially be included in the 4.x branch of Apache Cassandra. Until then, you can learn more about how to use SAI with some free online training [7].
SAI represents two things: firstly, this is a good opportunity to help Cassandra users create secondary indexes and improve how they can run queries at scale. Secondly, it’s an example of how we at DataStax are following up on our plans to increase contributions back to the community and leading with code. By making it easier to use Cassandra, this makes Cassandra better for everyone.
Links & Literature
[1] https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
[2] https://static.googleusercontent.com/media/research.google.com/en//archive/bigtable-osdi06.pdf
[3] https://en.wikipedia.org/wiki/Log-structured_merge-tree
[4] https://en.wikipedia.org/wiki/Trie
[5] https://users.cs.duke.edu/~pankaj/publications/papers/bkd-sstd.pdf
[6] https://cwiki.apache.org/confluence/display/CASSANDRA/CEP-7%3A+Storage+Attached+Index
[7] https://www.datastax.com/dev/cassandra-indexing




