
What can we accomplish as a community when we work together? If the Apache Cassandra community is any proof, quite a bit. We’ve built a pretty amazing database over the past 10+ years. We’ve also helped each other when learning how to run large scale distributed systems and we’ve been busy lately! I want to tell you about something to make your cloud-native data easy. A complete solution for Cassandra and Kubernetes that we are calling K8ssandra [1]. A collection of everything needed to run Cassandra wrapped up neatly in a Helm [2] chart.
Commit What You Learn (into Git)
When I first put Apache Cassandra in production at version .8, there was an expectation that to get it into production, you needed to be ready to do some work. That’s when I fell in love with the Cassandra community. I knew Cassandra would fit my use case, but I never felt alone in my quest as so many in the community helped me via email and chat. Eventually, I found myself sitting in this tiny square office with Patricio Echagüe, Nate McCall, and Ed Capriolo (all early committers), getting the last part of my code working and troubleshooting issues. At some points, we needed to commit code into Cassandra to fix the problems we found. Doing that assured the experience would be codified for future users. None of us worked for the same company but we shared a common passion for building scale infrastructure and cutting edge engineering. Over the years, and as infrastructure has evolved, we have worked as a continuously growing community to translate the hive mind of experience into code.
While we were off doing scale database operations and learning how to be Cassandra DBAs, a little project called Kubernetes started gaining traction and catching the attention of the same type of engineers deploying applications. Where DevOps was concerned with what needs to be done, Site Reliability Engineering (SRE) was asking about how it is done with automation and observability. Now SREs are looking at Cassandra with the same set of questions with a strong desire to use a single control plane. Running Cassandra in Kubernetes.
Bringing It All Together
You may have heard over the past year “Cassandra and Kubernetes go together like Peanut Butter and Jelly,” which is a fun way of saying they are a great fit. To be honest, when I say I like peanut butter and jelly sandwiches I’m not saying I want to make one. I would much prefer one already made! Same thing with infrastructure. Can I get something pre-assembled with sane defaults and the components I need? That is the spirit and the mission of K8ssandra. Besides the really catchy name, K8ssandra is meant to be more than a collection of tools. It is a collection of experience from our community of users, packaged and ready for everyone to use freely.
Running Cassandra in Kubernetes, and most stateful systems, require a set of knowledge you acquire by trial and error or by reading docs. This is a perfect time for just wanting the sandwich! It’s just like in those early days where we learned new things about deploying Cassandra and committed them into the project to help DBAs. The K8ssandra project is a place to commit knowledge for SREs deploying data services on Kubernetes with Apache Cassandra.
![]()
Kubernetes Training (German only)
Entdecke die Kubernetes Trainings für Einsteiger und Fortgeschrittene mit DevOps-Profi Erkan Yanar
The K8ssandra Unboxing
I’m sure you have seen the videos on YouTube where somebody opens some new product and describes the contents inside the box. That brings up a great point to make as we dig through the details of K8ssandra. This isn’t a single executable or a tarball to be unrolled. This is meant to be deployed using helm [3], a packaging tool for Kubernetes that makes installations easy. The real value in using K8ssandra is having everything you need for a typical running Cassandra cluster built, configured, and boxed up, ready to go. So let’s open the box and see what’s inside (Fig. 1).
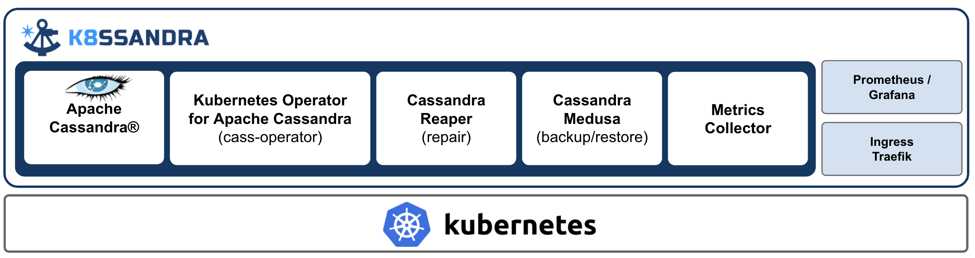
Fig. 1: Under the hood of K8ssandra
Apache Cassandra
The star of the show, but cast in a new and more contemporary light. Since the basic unit of deployment for Cassandra is the node, it nicely complements the composability preferred by Kubernetes. Stateful workloads in Kubernetes can be a bit of a challenge, but the Dynamo model of databases [4] allows us to do the most basic primitives in elastic, scaling, self-healing data services. Worth noting, the Cassandra project community has embraced Kubernetes as a control plane for Cassandra. Expect to see a lot of changes post 4.0 [5] that will make running in Kubernetes much more efficient. Meanwhile, you’ll get something that runs properly in a Kubernetes environment with very little maintenance.
cass-operator
The most critical element of bridging Kubernetes and Cassandra is the operator. The Cassandra community has been focusing much attention on operators over the past two years as the appropriate starting place. If there is magic happening, it’s all in the operator. It serves as the translation layer between the control plane of Kubernetes and actual operation done by the Cassandra cluster. Recently, the Apache Cassandra project has agreed on gathering around a single operator called cass-operator [6]. Some great contributions from Orange with CassKop [7] will be merged with the DataStax operator and a final version will be merged into the Apache project. This is the best example of actual production knowledge finding its way into code. Community members contributing to cass-operator are running large amounts of Cassandra in Kubernetes every day.
Cassandra Reaper
Reaper is a tool that helps manage the critical maintenance task of anti-entropy repair in a Cassandra cluster. Originally created by Spotify, later adopted and maintained by The Last Pickle, Cassandra Reaper [8] is now a sub-project of Apache Cassandra. If you were to sit a group of Cassandra DBAs down to talk about what they do, chances are they would talk a lot about running repairs. It’s an important operation for Dynamo based systems as it keeps data consistent despite inevitable issues that happen like node failures and network partitions. That’s really all you need to know because in K8ssandra, Reaper runs it for you automatically! And because this is built for SREs, you can expect a good set of pre-built metrics to verify everything is working great.
Cassandra Medusa
Can’t say it’s in production correctly if you don’t have a way to backup and restore your data. Same as Reaper, Medusa [9] is now a sub-project of Apache Cassandra via Spotify and The Last Pickle. Backing up a distributed system takes a different approach than most DBAs have done. Medusa not only helps coordinate those tasks, but it manages the placement of the data at rest. The initial implementation allows backup sets to be stored and retrieved on cloud object storage (S3 buckets) with more options on the way. Probably the most interesting feature is the restore. Not for bringing back damaged databases but for fast hydration of your test clusters in a CI/CD pipeline. I can’t wait for the first conference talks on creative ways SREs will be using this tool.
Metrics Collection and Output to Prometheus
Rounding off the SRE wish list is that all-important observability component. Right in line with the mantra of “measure everything” K8ssandra comes pre-configured with a great collection of metrics that need to be in place for a cluster. Cassandra has a lot of metrics that can tend to be overwhelming for a new user. Not only curating the most important and useful metrics, but creating pre-built Grafana dashboards (Fig. 2) to help you make sense of them. There are even discussions happening about adding Jaeger tracing. You should see a lot more happening in this component as this is a huge area of Kubernetes and operators add in their favorites. If you are interested in contributing as an SRE, this is a great place to start.
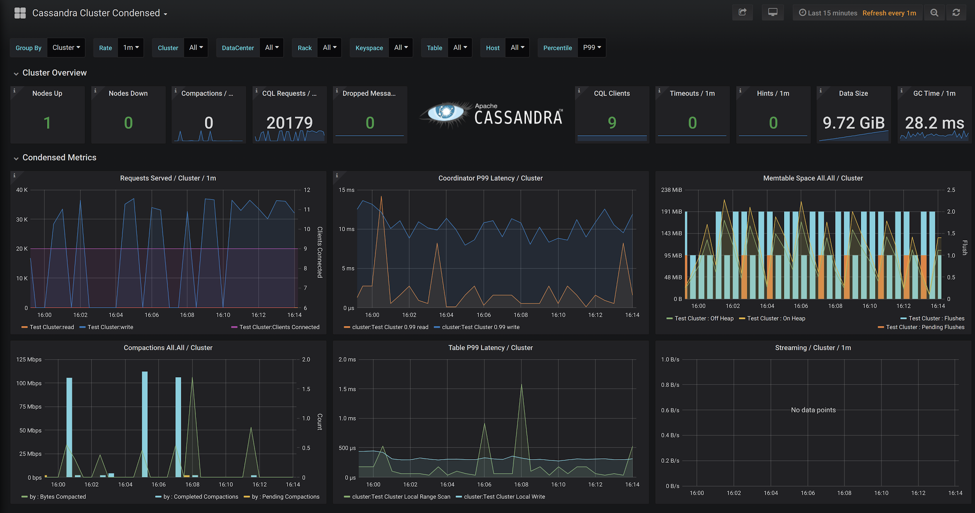
Fig. 2: Example of an Grafana dashboard made with K8ssandra
Lets Chart an Awesome Future
That’s what is in the box today, but it’s time for our community to get around K8ssandra and pave the way once again. Already, K8ssandra has benefited from contributions from Spotify, Apple, Instaclustr, Orange, New Relic, DataStax, and many other engineering organizations. We’ll be learning much more as a community as we make Cassandra the default data plane for Kubernetes. When we do, those learnings will be committed into the next version of K8ssandra and make it that much better.
If you are ready to give it a try or want to learn more about how you can participate, we have created the first stop at K8ssandra.io [1]. There you can get easy instructions on how to get started or if you want to connect with the community and become a part of the project. This is early days for what I think will be an exciting project as we move forward together as a community. There is a lot of Cassandra in use and a lot of Kubernetes. They aren’t always together so let’s use this as a place to gather and make that happen!
DataStax holds hands-on workshops at different times so make sure and check the DataStax Workshop eventbrite page [10] for any upcoming events that might work for you, or try our free hands-on learning scenarios anytime at DataStax/dev [11]. Additionally, DataStax will be rolling out new certifications for running Cassandra in Kubernetes. If you are interested, you can register for notifications of when those are available [12].
If you are a DBA looking to become an SRE, this is a great place to start. Building cloud-native applications [13] is the future and data on Kubernetes is a key part of that future. I’m looking forward to building that future together.
Links & Literature
[1] https://k8ssandra.io
[2] https://helm.sh
[3] https://helm.sh
[4] https://en.wikipedia.org/wiki/Dynamo_(storage_system)
[5] https://cassandra.apache.org/blog/2020/07/20/apache-cassandra-4-0-beta1.html
[6] https://github.com/datastax/cass-operator
[7] https://github.com/Orange-OpenSource/casskop
[8] http://cassandra-reaper.io
[9] https://github.com/thelastpickle/cassandra-medusa
[10] https://www.eventbrite.co.uk/o/datastax-23222864038
[11] https://www.datastax.com/dev/kubernetes?utm_medium=article&utm_source=pr&utm_campaign=k8ssandra
[12] https://www.datastax.com/dev/certifications?utm_medium=article&utm_source=pr&utm_campaign=k8ssandra
[13] https://www.datastax.com/cloud-native?utm_medium=article&utm_source=pr&utm_campaign=k8ssandra




