
No related posts found.
Atruvia AG, a digitalization partner within the “cooperative financial group,” offers IT solutions tailored specifically to banks in the areas of banking and information technology: from data center operations and the Atruvia banking system to app development.
To understand the hurdles that needed to be overcome, it is important to know the starting point. It all began with a classic standard stack (Fig. 1):
- Fat-Swing-Client: approx. 700 MB, nearly 6,000 individual functions
- Middle Tier: over 985 Java modules, over 15,000 services, and over 21 million lines of code (LoC)
- Mainframe: COBOL and Java, over 115 billion transactions in 2022

Figure 1: Atruvia AG – Starting Point
The company was organized according to a traditional hierarchical structure, which increased complexity and hindered operations. There were only two rollouts per year, maintenance work took place at night, and the level of automation was low. At that time, teams worked in greater isolation than they do today, which made communication and collaboration more difficult and led to rigid processes and slower response times.
Goal: Foster self-motivation through autonomy
The goal was to create a modern, scalable architecture that supports the company and its customers in developing and operating innovative and secure solutions, with the necessary agility. Faster deployments and enhanced observability are crucial for improving and continuously monitoring quality and performance. These goals are not merely technological in nature; they also require a cultural shift toward greater responsibility and initiative. The goal is to reduce legacy systems and complexity and leverage the benefits of a private or public cloud. To this end, containers and microservices should be introduced. Team structures should change to create autonomous, self-managed teams that can deploy their services and applications at any time. This autonomy fosters motivation and innovation while minimizing dependencies on other teams. Through clear macro-architecture guidelines and end-to-end responsibility for their products, the teams were able to work more efficiently and independently.
The biggest challenge for the teams was adapting to new ways of working following the numerous changes of recent years and the introduction of agile methods and overcoming the previously rigid and isolated structures. The development teams, in particular, had to continually adjust to new processes, technologies, and organizational structures, which required constant adaptation and flexibility.
Where does the company stand today: The example of an omnichannel platform
The company provides an omnichannel platform (OKP), a technical platform that enables the seamless design of banking solutions across channels and between channels. It supports various forms of interaction between customers and banks. Currently, our omnichannel platform team supports over 150 development teams with more than 300 projects (OpenShift namespaces). In 2023, the team implemented over 3,200 deployment tasks (and counting). Nearly all teams work in sprints with a 12-week PI (Portfolio Increment) cycle. The technology stack was assembled from the cloud-native landscape, enabling a flexible and future-proof infrastructure.
Financial Sector Regulation: Between Challenge and Opportunity
The financial sector is highly regulated, which requires specific systematic approaches to ensure the proper management of sensitive information. These include standards such as BSI Basic Protection, PCI DSS, and PSD2:
- BSI Basic Protection: A standard established by the German Federal Office for Information Security (BSI) that provides methods and measures for information security
- PCI DSS: A globally recognized security standard for the protection of credit card data
- PSD2: An EU directive aimed at promoting secure payment services and innovation in the payments market
- BaFin: German supervisory authority for banks, financial service providers, insurance companies, and securities trading, to ensure the stability and integrity of the financial system. In this context, the Minimum Requirements for Risk Management (MaRisk) and the Banking Supervisory Requirements for IT (BAIT) play a central role, as they define the regulatory requirements for risk management and IT security in these institutions.
This gives rise to numerous regulatory requirements that must be taken into account and implemented. These standards require systematic approaches to managing sensitive information in order to ensure confidentiality, integrity, and availability through risk management processes.
- For example, a strict policy prohibits development teams from performing direct deployments to the production environment. This complicates or prevents the implementation of continuous deployments.
- To ensure the necessary protection of IT systems, authorization concepts must be created in accordance with the “need-to-know” and “least privilege” principles, regularly reviewed, and adapted to current security requirements; this can be achieved, for example, by setting time limits on access permissions and implementing segregation of duties.
- Another example of one of these requirements is that all relevant IT systems and processes, particularly those supporting time-critical activities, must be regularly checked for vulnerabilities and secured through appropriate measures. In practice, this means that every update or change to a subsystem must undergo careful testing and validation to ensure that the security and integrity of the overall system are not compromised.
These constantly evolving regulatory requirements and changing threat landscapes challenge teams to keep their systems compliant and secure at all times.
STAY TUNED
Learn more about DevOpsCon
End-to-End Responsibility
The teams are responsible for the IT product. There are no separate project and support teams to avoid handovers and the potential loss of knowledge that can result. This approach goes hand in hand with cross-functional teams. Instead of the previous division into separate silo teams, the responsible product team should possess all the necessary expertise to manage the entire lifecycle of an IT product, from conception to decommissioning. These approaches support a product-centric way of working and improved customer focus. The team is not only responsible for its products and services but also ensures their stable operation. At the same time, direct customer feedback is incorporated into both the design and support phases, enabling continuous improvement and adaptation to customer needs.
All of this presents significant challenges: How can autonomy be achieved in teams of eight to twelve people each, especially given 24/7 support and over 200 bounded contexts that must be handled differently depending on their criticality?
Introduction to SRE
To optimize collaboration and operations in light of the new requirements, another approach had to be integrated alongside DevOps: Site Reliability Engineering (SRE). This methodology was originally developed by Google to ensure that systems are always available, efficient, and scalable. The main focus of SRE is on reliability, scalability, automation, and efficiency.
SRE uses measurable metrics such as SLIs (Service Level Indicators) and SLOs (Service Level Objectives) to quantify reliability. An important aspect of SRE is the automation mindset: “eliminate toil,” meaning that all repeatable tasks should be automated. There is an error budget, which is the percentage of time a service is allowed to deviate from an SLO, and which is used as a buffer for planned downtime and testing.
DevOps vs. SRE
DevOps and SRE complement each other (Fig. 2) and each has specific practices and goals, which are briefly summarized in Table 1.
| DevOps | SRE |
|---|---|
| Supporting collaboration between the development and operational divisions | An approach to IT operations focused on reliability and stability |
| Goal: Increase the speed and agility of software development | Goal: Minimize downtime and system outages |
| Focus on software development | Implementation of DevOps principles and practices |
Table 1: DevOps and SRE
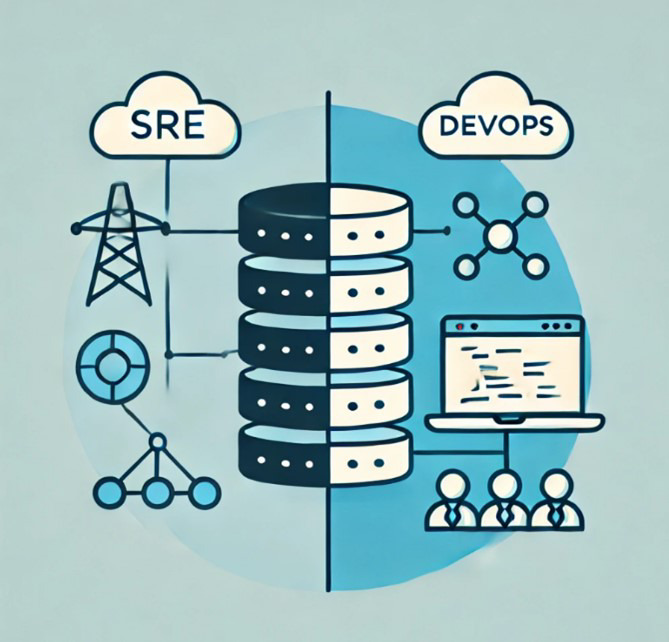
Figure 2: SRE and DevOps complement each other
DevOps establishes the cultural foundation for collaboration, while SRE provides specific practices and goals for reliability. Depending on the maturity level of the development teams, varying degrees of support are required.
Adapting to the environment
Because the company operates in a highly regulated environment, SRE cannot be implemented in its purest form. The SRE team works closely with the development teams, with a focus on system stability. Both teams support each other in incident response management, infrastructure management, and matters related to security and compliance. Their responsibilities include (Fig. 3):
- Deployments
- Monitoring
- Automation
- Operational and Service Responsibility
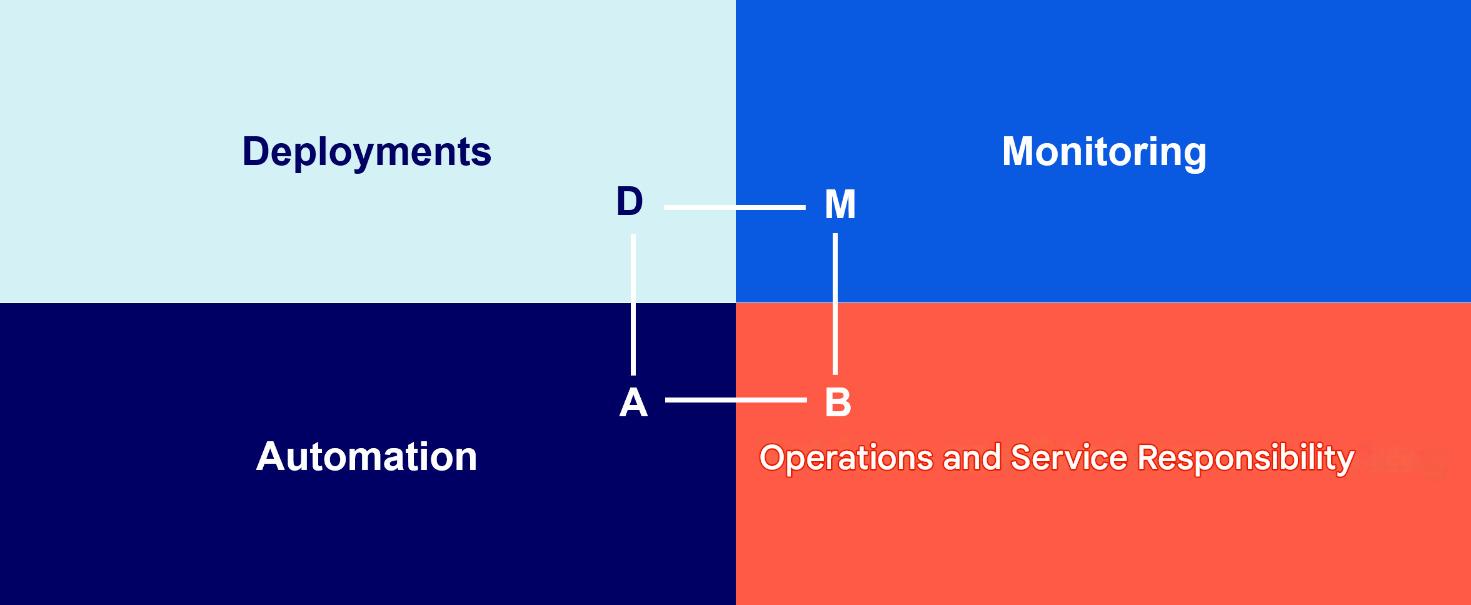
Figure 3: Areas of responsibility
These tasks can only be accomplished through the joint effort and collaboration of all teams. Although the teams are responsible for the entire lifecycle of their products, they are supported by the SRE team on call, among others. When appropriate alerts are triggered or following a call from first-level support, the SRE team conducts the initial investigation of the incident, restores service (e.g., by rolling back to a previous version), and ensures that the system is up and running again as quickly as possible. If necessary, the development teams perform the final troubleshooting during regular business hours. In addition, members of the SRE team also assist with issues during business hours to minimize the impact on operations. The SRE team also conducts post-mortem analyses together with the other teams to identify the root causes and prevent future incidents.
Important information and best practices are shared within the “DevOps Community of Practice” to promote continuous improvement and knowledge transfer.
Kubernetes Training (German only)
Entdecke die Kubernetes Trainings für Einsteiger und Fortgeschrittene mit DevOps-Profi Erkan Yanar
Tools and Automation
To scale collaboration across multiple teams, the use of appropriate tools is essential. It is important not only to rely on existing solutions but also to consider developing custom tools tailored specifically to particular use cases. It is equally crucial to optimally integrate off-the-shelf products to ensure seamless collaboration and, consequently, increased efficiency. This can be critical to ensuring efficient and effective solutions that are specifically tailored to a company’s unique challenges and needs. Examples of such customized tools include:
- Microservices Overview: a custom-built tool for managing and monitoring microservices (e.g., resource usage of namespaces in OpenShift [Fig. 5], service version overview)
- Open-Source Policy Engine for Kubernetes: customized and extended to visualize and validate configuration best practices (Figs. 6–8)
- Deployment Dashboard: Visualization of deployment tasks in Jira to display and log data and dependencies (Fig. 9)
- Monitoring and Alerting: Use of tools such as Dynatrace, Prometheus, and Grafana
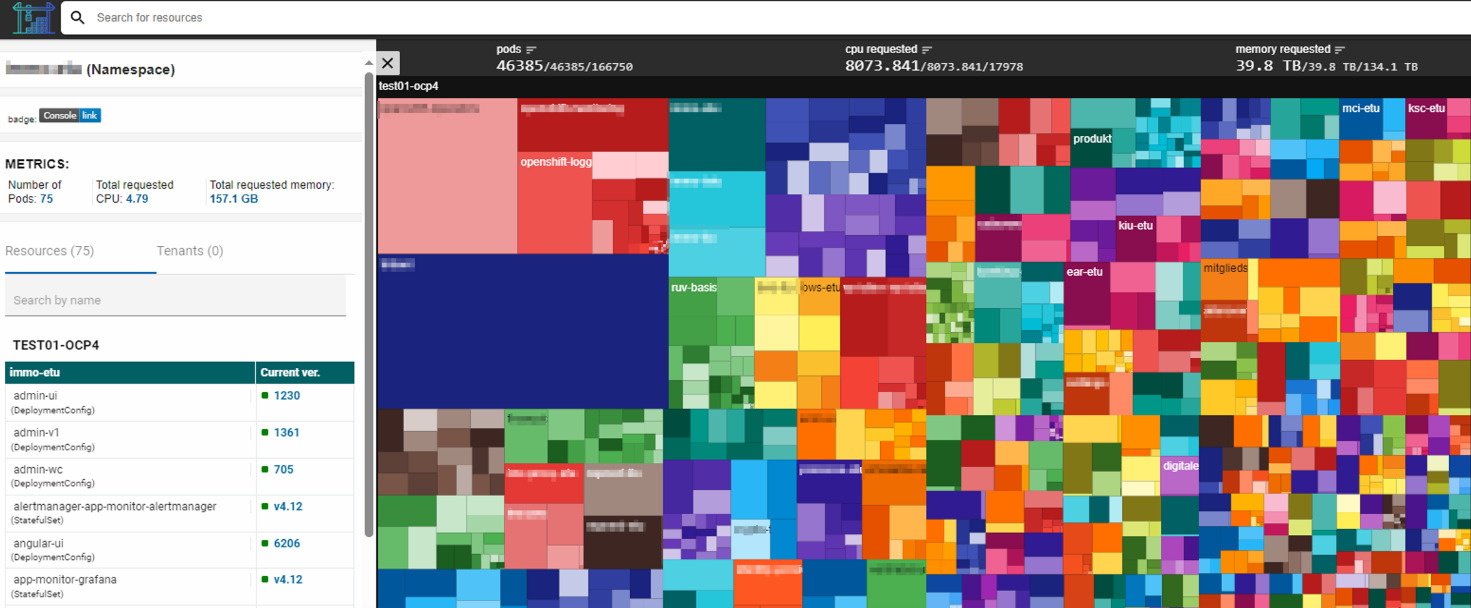
Figure 4: Resource usage of namespaces
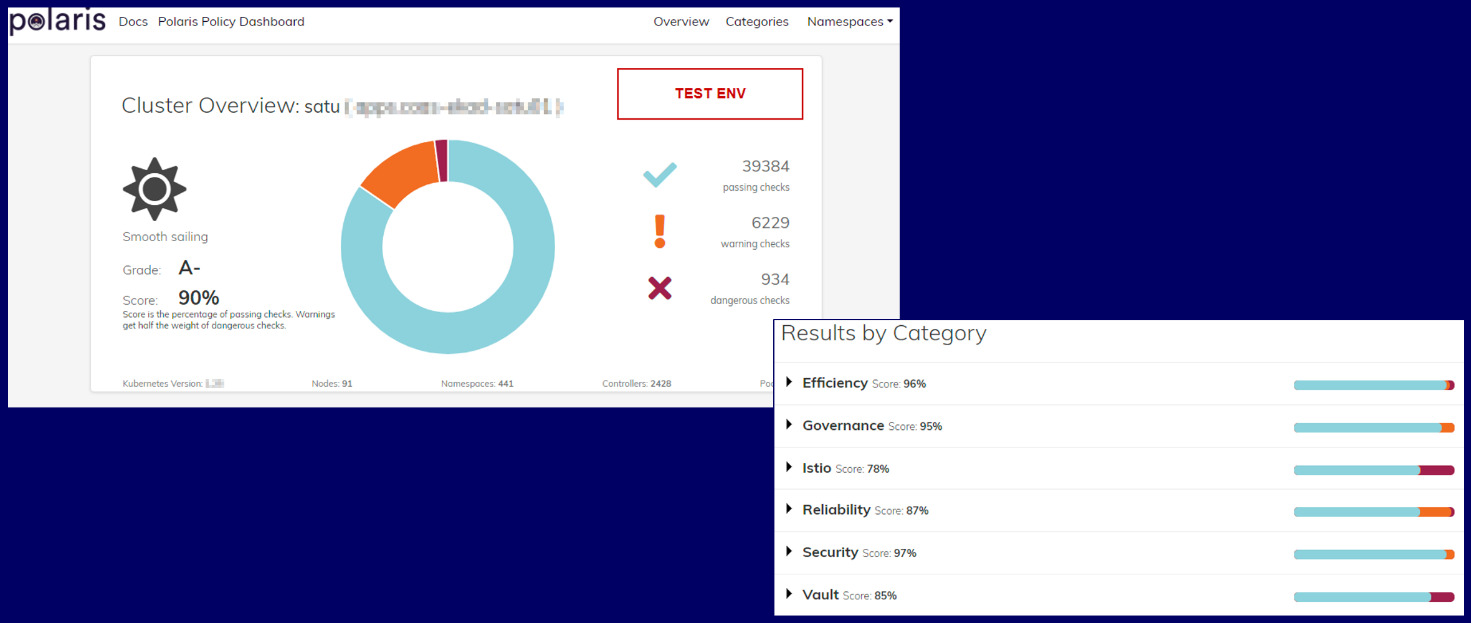
Figure 5: Policy Dashboard
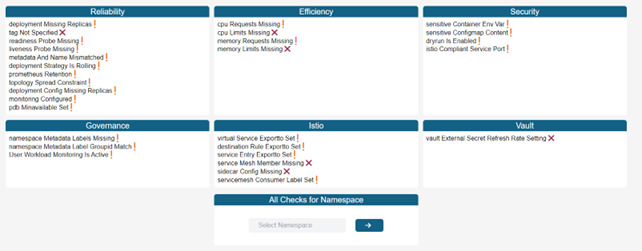
Figure 6: Visualization of the implementation of best practices for configuration
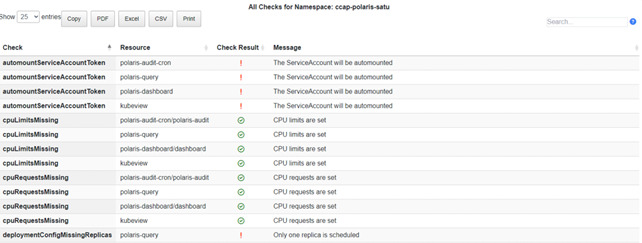
Figure 7: Checks for Namespaces
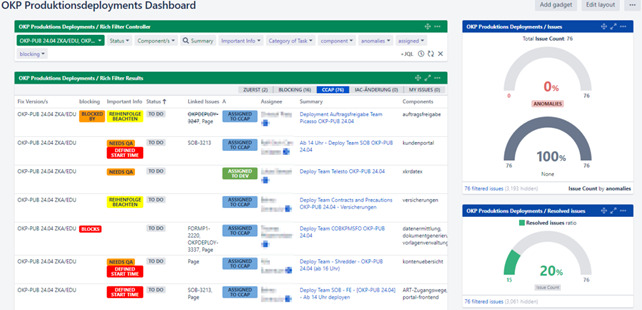
Figure 8: An Overview of Production Deployments
In the CI/CD domain, GitOps and the standardized “Golden Pipeline”—which is identical for all users—are used. This approach allows specific regulatory requirements to be delegated to the technology. As a result, teams can focus on their core tasks without having to deal with regulatory requirements that have already been met.
Conflicts between teams and SRE
To ensure clear priorities and the ability to take action, it is important to develop a shared understanding of the role of SRE. Teams must understand that the availability and stability of their services must be taken into account. Autonomous SRE teams need the authority to act so they can respond promptly when agreed-upon availability is not met. This is particularly challenging when the SRE mindset must first be introduced to existing teams. It requires close collaboration and clear communication between the teams and the SREs.
Key Takeaways
DevOps and SRE
- DevOps and SRE complement each other and form a solid foundation for reliable IT operations.
- Strengthening the mindset and fostering a culture of feedback is crucial. Mistakes are okay, as long as we learn from them.
Observability
- Implementing SLOs is essential for measuring and improving performance.
- A transparent and straightforward alerting system that integrates with existing incident management processes is necessary.
Tools
- Teams shouldn’t be overwhelmed with a multitude of tools. It’s more important to use the right tools for each specific use case.
- Customizing and developing your own tools to meet specific needs can be a good idea.
Focus on teams
- Training, development, and onboarding of teams are crucial to success.
- Show-and-tell sessions, onboarding universities, improvement days, and team consultation hours promote collaborative learning.
- Striking a balance between autonomy and guidelines is important to avoid chaos and minimize technical debt.
- Communities of Practice (CoP) should be relevant and well-organized.
- Teams need the freedom to make decisions. This is the only way innovative ideas can emerge.
Atruvia’s DevOps and SRE journey demonstrates that continuous adjustments and optimizations are essential to creating a successful and scalable environment. By striking the right balance between culture, technology, and processes, we can build a stable and innovative IT landscape that meets our customers’ needs.
Regulatory requirements undoubtedly pose a particular challenge in the financial sector, but through targeted strategies and the integration of compliance into our development process, we are able not only to overcome these hurdles but also to use them as an opportunity to improve our practices.
Even though significant progress has been made, the journey is not yet over. As the boundaries of technological innovation continue to expand, there is always something new to discover—not
🔍 FAQ
1. How does SRE differ from DevOps in a regulated environment?
While DevOps focuses on breaking down silos and increasing development speed through cultural change, SRE (Site Reliability Engineering) provides the specific engineering practices to ensure system stability. In regulated sectors like banking, SRE acts as a bridge—using automation and "error budgets" to manage strict availability requirements (like BaFin or PSD2) without sacrificing the agility gained through DevOps.
2. What are the biggest challenges when moving a legacy banking stack to DevOps?
The primary hurdles include managing high technical debt (e.g., large mainframes and massive Java monoliths) and navigating rigid regulatory frameworks. Atruvia’s transition highlighted that the shift is as much cultural as it is technical: teams must move from a "siloed" mindset with twice-yearly rollouts to a model of end-to-end responsibility and continuous, automated deployments.
3. Can you implement Continuous Deployment (CD) in the financial sector?
In highly regulated environments, strict "segregation of duties" often prohibits developers from deploying directly to production. To overcome this, Atruvia utilizes a "Golden Pipeline" and GitOps workflows. This allows teams to automate security and governance checks within the code itself, ensuring that deployments remain compliant and audited while still achieving high frequency and speed.




