
An Advanced MLOps Lifecycle
Machine Learning is exploratory and data-driven [1]. It is about extracting patterns from data and reapplying those patterns to new data. If all goes well you get good predictions. The exploratory part is finding the right patterns for the data you intend to make predictions on.
When the data is not well-structured or predictable then the MLOps lifecycle can look very different to mainstream DevOps. Then we see a range of approaches come in that are specific to MLOps (Fig. 1).
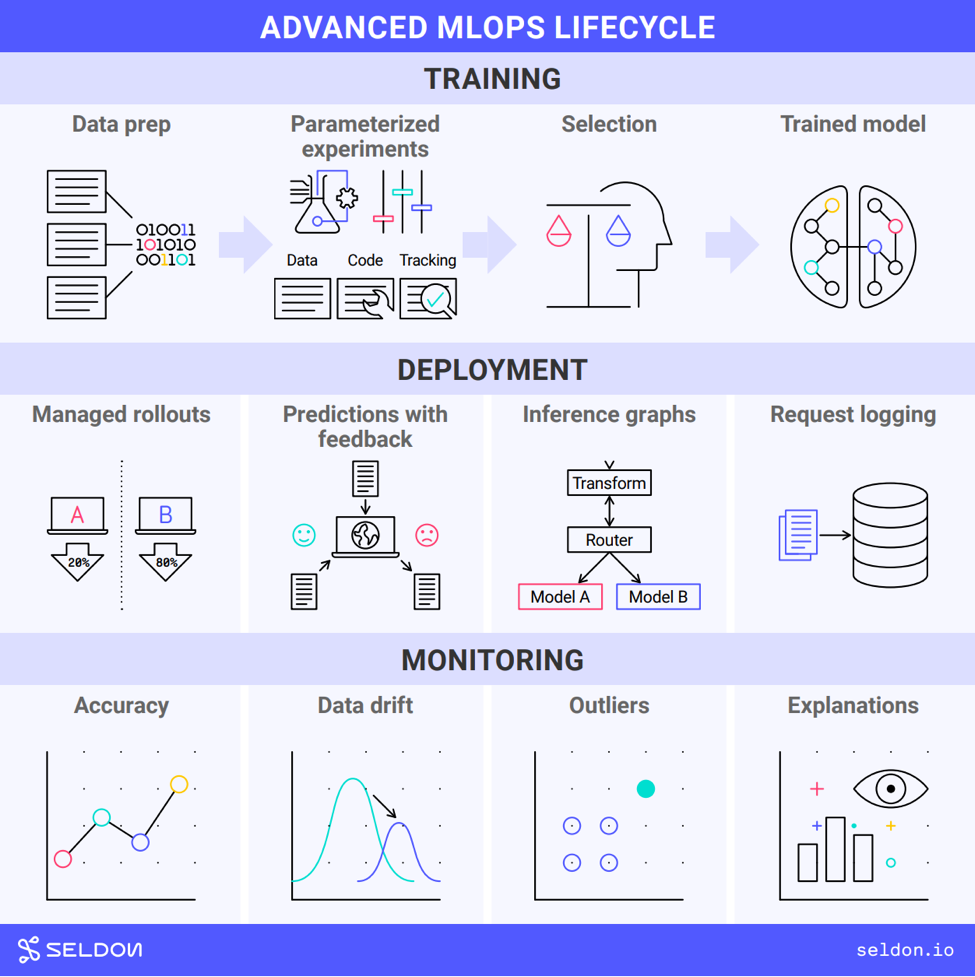
Fig. 1: Image by Seldon / CC BY-SA 4.0 license
Let’s go through each of the phases in turn. We’ll look at the approaches that come into play and see what MLOps need motivates each approach.
Training
Training is about finding the best patterns to extract from training data. We encapsulate these patterns in models. Training runs have parameters that can be tweaked to result in different models. Encapsulating the best patterns in models is exploratory (Fig. 2).
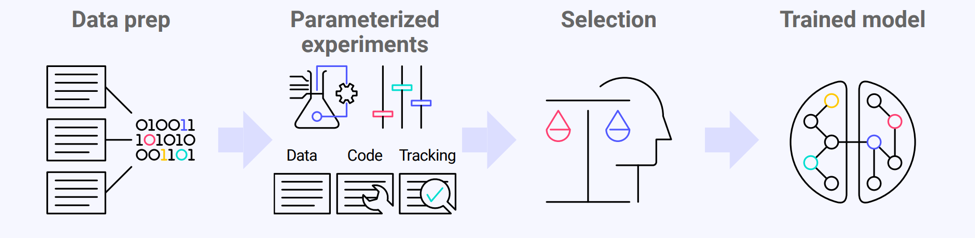
Fig. 2: Image by Seldon / CC BY-SA 4.0 license
To explore parameters for the best models it makes sense to run multiple jobs in parallel. This is done in a hosted training environment running a specialist training platform. The best model for deployment then needs to be selected and packaged.
Data is a big part of why these platforms are run hosted rather than on a Data Scientist’s laptop. The volumes can be large. And data rarely starts ready for training models. That means a lot of preparation needs to be performed on it. This can take a lot of time and hardware resources. For governance and reproducibility reasons the preparation operations might also all need to be tracked.
Deployment
When we’ve selected a new model then we need to work out how to get it running. That means determining whether it’s really better than the version already running. It may have performed better on the training data but the live data could be different (Fig. 3).
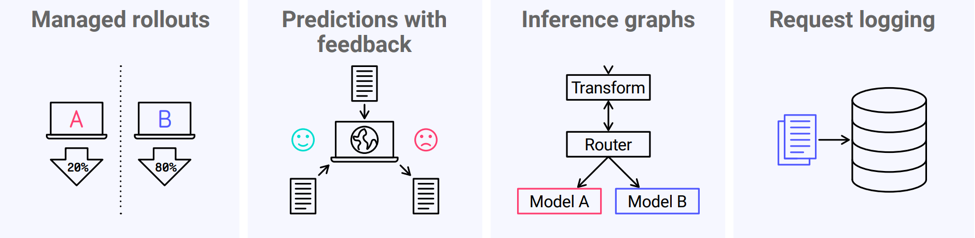
Fig. 3: Image by Seldon / CC BY-SA 4.0 license
MLOps rollout strategies tend to be cautious. Traffic may be split between the new model and the old model and monitored for a while (using an A/B test or canary). Or the traffic may be duplicated so that the new model can receive requests but just have its responses tracked rather than used (a shadow deployment). Then the new model is only promoted when it has been shown to perform well.
We need to know a model is performing safely in order to promote it. This means deployment needs support from monitoring. We can also find that deployment may need to support a feedback mechanism for optimum monitoring. Sometimes a model makes predictions that turn out to be right or wrong e.g. whether a customer chose a recommendation. To make use of that we’d need a feedback mechanism.
An advanced case of splitting traffic for optimization is use of multi-armed bandits. With a bandit the traffic is split in a continuously adjusting way. The model performing best gets most of the traffic and the others continue to get a small portion of traffic. This is handled by an algorithmic router in an inference graph. If the data changes later then a lesser-performing model may shift to becoming the dominant model.
Deployment can be intimately tied to monitoring. Deployment tools such Seldon therefore not only support deployment-phase features but also have integrations for the MLOps needs of the monitoring phase.
Monitoring
Monitoring for model accuracy is possible only if you have feedback. This is a good example of a monitoring feature needing a deployment-stage feature. In some cases live accuracy may be the key metric and in other cases a custom business metric may be more important. But these are only part of the monitoring picture.
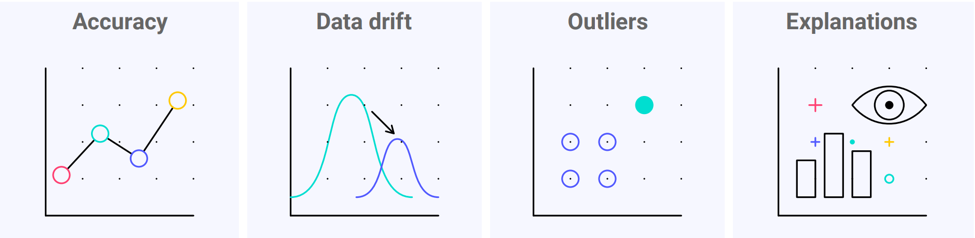
Fig. 4: Image by Seldon / CC BY-SA 4.0 license
The other side of ML monitoring is seeing why a model performs well or badly. That requires an insight into the data.
A top reason why model performance may drop is a change in the live data. If the data distribution shifts away from the training data then performance can drop. This is called data drift or concept drift.
Even if the overall distribution remains in line with the training data, some predictions may still be dramatically wrong. This could happen if some individual data points are outside of the distribution. These outliers can be damaging in cases where predictions need to be reliable across the board.
Fully understanding why a model made a certain prediction can require looking at how a model makes predictions and not just the input data. Explanation techniques can reveal the key patterns that a model is relying on for its predictions and show us which patterns applied to a particular case. Achieving this level of insight is a data science challenge in itself.
There are different approaches to achieving advanced monitoring. At Seldon we make heavy use of asynchronous logging of requests. Logged requests can then be fed into detector components to monitor for drift or outliers. Requests can also be stored for later analysis e.g. explanations.
Understanding the MLOps Lifecycle
There’s much to practising MLOps projects that we’ve not covered here. We’ve not talked about estimation, scheduling or team composition. We’ve not even got very far into the tool landscape [2]. Hopefully what we have achieved is to understand the key motivations.
We’ve learnt to understand the MLOps lifecycle in terms of a set of needs. We’ve seen that ML is about taking patterns from data and reapplying those patterns. Data can be unpredictable and that can mean we have to be cautious about rollouts and that we have to monitor at the level of data and not just errors.
Links & Literature
[1] https://hackernoon.com/why-is-devops-for-machine-learning-so-different-384z32f1
[2] https://github.com/EthicalML/awesome-production-machine-learning




