

But if you leave the familiar home of developers, administrators, and IT departments and force yourself into the perspective of a business unit dependent on delivery from IT, you might find it sobering to discover that the improved speed brought about by modern technologies is rarely perceptible from the outside. Why is that?
There are many reasons why users and customers do not perceive the speed improvements of DevOps and continuous delivery in particular from the outside. Often, major difficulties lie in team collaboration and communication [1], but tools and technologies are rarely suspected. This is probably why all sorts of DevOps tools are booming. But experience shows that building and using continuous delivery tools alone does not necessarily lead to success. Once again, the time-honored wisdom of Grady Booch applies: “A fool with a tool is still a fool”.
The Continuous Delivery Pipeline
To understand the seven pitfalls, we first need a common understanding of a modern continuous delivery pipeline (Fig. 1). The goal of such an automated delivery pipeline is to put changes into production as frequently as possible, and then get feedback from real users and customers as quickly as possible. In the end, systems emerge more quickly and are tailored to the actual needs of those who are to receive help and relief in their private or professional lives.
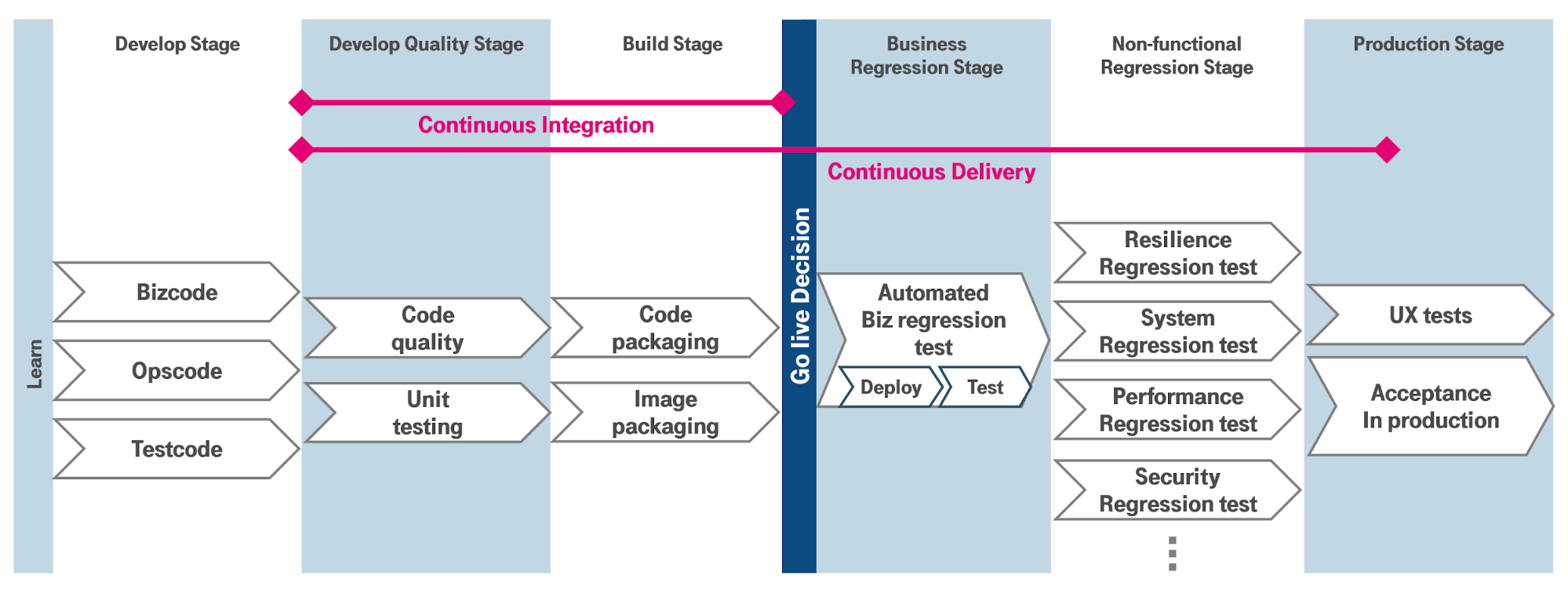 Fig. 1: Idealized DevOps delivery pipeline.
Fig. 1: Idealized DevOps delivery pipeline.
Typically, a cross-functional team in agile mode works on features in the development stage, which it develops in a sprint, validates through testing and finally rolls out in an automated manner. In contrast to the classic approach, the development work and all manual activities in general should be bundled here (“shift left”). The developer quality stage of continuous integration serves to ensure that the group responsible for the feature delivers an executable enhancement with a minimum quality level. In addition to code scanners, unit tests document difficult pass paths through the code and check for correct behavior in the rain, i.e., not-so-positive passes (rainy day scenarios). After that, the build stage not only builds libraries and other runtime fragments. In continuous delivery, additional delivery packages (called images) are built, which the pipeline later installs unchanged in the various regressions until production.
STAY TUNED
Learn more about DevOpsCon
Before making a production decision, the team works until it can hand the implemented feature to a user with a clear conscience. In addition, continuous integration must be “green,” meaning that it passes through the appropriate stages successfully. A product owner then decides, together with the team, whether the feature will go into production. This is also the decision that the continuous delivery pipeline starts and runs through to production unabated.
Since the initial situation may have changed in the meantime, continuous delivery first runs through the integration stages again. All further stages serve to avoid possible overlooked side effects on functions that have already been rolled out. The business regression looks for functional effects and, if possible, runs all previously performed functional tests automatically for this purpose. Non-functional regressions are used to detect technical influences such as reduced performance of dependent features. They also help to safeguard areas that may not have been the focus of the team at the time (such as system security). For each of the test areas, the pipeline installs fresh production environments to practice rollout to production.
Specialist approvals are not mandatory in this scenario. It is actually the users of a system who decide whether a feature actually works or not. Continuous delivery successfully ends with a runnable installation in production and the successful first use of the new feature by a user.
The whole design sounds reasonable and is frequently used by many companies. So what could possibly go wrong?
Pitfall 1: An inappropriate branching strategy
Version-controlled development has become an integral part of all professional development methodologies. However, despite flexible tools like Git, the ill-advised use of branches (development forks) can end up a nightmare.
Branches are popular because they allow you to deviate from the main development at any point and get an extension up and running with a few people first, undisturbed by the rest. They allow for undisturbed work. Unfortunately, branches have the unpleasant property of aging quickly. The longer a team works independently of the main branch, the harder it becomes to bring the two development threads back together. It gets really bad when you allow someone to only merge finished features at the end of the sprint or even at release. Merge hell is perfect when someone may not even be the original developer of the feature. For an entertaining account of this purgatory where kings and heroes are born, see [2]. In any case, extended, late merges are a waste of time and usually also an uncontrollable delivery risk.
To avoid this, for years, Google has publicized completely abandoning branches and operating only on a common main branch. But isolation also creates the opportunity to work carefully in peace or to share partial results with team members in advance behind the scenes. Branches have a right to exist after all.
A good middle ground is to allow only simple feature or bug-fix branches. The main purpose of trunk-based development is to be able to green-light the continuous delivery stages carefully, with peace of mind, and in cooperation with other people. More details can be seen in Figure 2. This insight now seems to have reached Google as well [3].
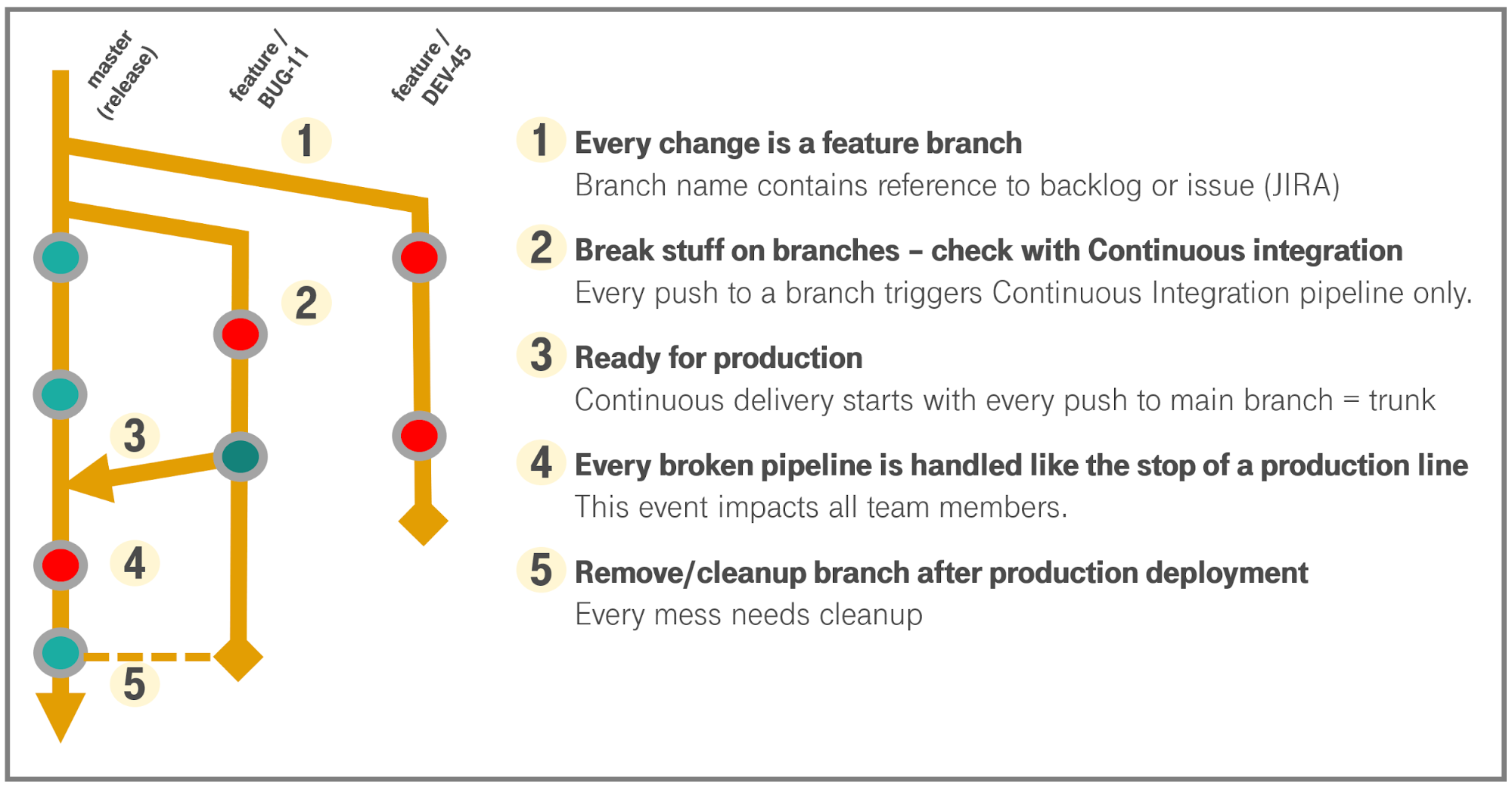 Fig. 2: Diagram of trunk-based development
Fig. 2: Diagram of trunk-based development
Pitfall 2: No standard pipeline – tool overkill
A few years back, the State of DevOps Report 2014 [4] showed that free choice of tools for teams contributes to job satisfaction and thus productivity. Conversely, there was no clear indication that standardizing tools has a positive effect. In fact, there are organizations and projects where the people choosing the tools aren’t even the ones who have to work with them. Such standardization is coercion without benefit.
Both are taken by many DevOps groups as justification for each team to pick and build everything themselves. But this is a misunderstanding. Of course, developers should work with tools they are comfortable with. But it doesn’t make sense, for example, for each team to pick its own source code repository or DevOps chat tool. This kind of thing hinders information sharing and collaboration across team boundaries. In addition, it also costs an unnecessary amount of energy and time if everyone has to ensure the runnability, availability and data security of their own system. It’s important to remember that in DevOps delivery mode, the continuous delivery pipeline is mission critical.
Also, tools that require a deep understanding of how they work should be picked by all teams together. Rather than one person on each team learning a siloed solution, standardization creates a pool of those knowledgeable about a common product.
However, there are tools that support each team’s specialization, making their lives easier (e.g., business intelligence evaluation tools). Here, standardization and restriction would be counterproductive – and often they can be easily integrated into the delivery pipeline used by the team. So why ban them?
This realization also means that each team is allowed to build its own supply pipeline. So the tool used to process pipelines should be the same for all teams, but not the processes mapped into it. It is similar for firefighters: the essential tools such as hoses, are standardized. But, there are also tools such as special extinguishing agents which are necessary or particularly effective in certain operational scenarios, but not every firefighter can or wants to handle them.
Pitfall 3: Immutable installations – not really
Immutability is a concept from functional programming. This concept is always used where one wants to avoid errors by forbidding the modification of a once correctly built structure – be it a data structure in a program or a piece of infrastructure. Instead, any modification requires a recalculation or rebuilding of the structure.
So-called immutable installations and infrastructures are an important mechanism in continuous delivery. The idea is to make installations repeatable in different environments without risk.
Installations often surprisingly fail because they are suddenly confronted with an initial situation that is different from anything that has gone before (Fig. 3).
 Fig. 3: Immutable installations
Fig. 3: Immutable installations
The reason for this effect is that system environments have aged or deviated unintentionally and in unnoticed ways due to manual intervention.
Immutable installations are used to avoid this effect and to make the rollout of systems reliably repeatable. The idea is to minimize the number of assumed prerequisites for an installation and to rebuild as much as possible automatically from scratch in each case. So more tear down and rebuild, less administrative fiddling around. If you have done this well, you can build any number of new environments at the push of a button.
Unfortunately, in practice, you still find automations that use state-of-the-art tools, but are not immutable at their core. Common sources of error are:
- Infrastructure and software installation remain separate and are even managed by different people. Infrastructure continues to be built less frequently because of the effort involved, teams install software multiple times on the same environment.
- Software is rebuilt specifically for different environments. This means that, strictly speaking, you have a new test object in each environment.
- Although perhaps the same image (Docker or virtual servers) is used in all environments, there are completely different orchestration scripts for different environments.
In such cases, one is still forced to budget time for debugging inconsistencies for each environment. With working immutable installations, over time there is a confidence in automated tear down and re-roll out because it has worked the same way many times before production.
Pitfall 4: Not stopping the production line
Not every launch of a continuous delivery pipeline is successful. There are two root cause areas for this:
- At least one regression test has failed.
- An automated installation aborts with an error.
In the DevOps community, there is a consensus that this state is equivalent to a factory production line standstill. From the lean production system, we learn that this situation is a form of jidoka (automated production stop) [5], and that restarting production is now top priority for those working on this production line.

Better Continuous Delivery with microservices
Explore the Continuous Delivery & Automation Track
But the IT project manager in the wild tends to see it as a waste for the whole team to survey the shutdown. Instead, there are two typical reactions: With the “back to the silo” principle, the respective expert should obligingly fix the problem, which usually means the developer or the administrator in the case of installation errors. With the “polluter pays principle”, the person who created the last change is supposed to solve the case.
Both, however, contradict the experience that errors in continuous delivery often uncover side effects that the individual expert has overlooked from his point of view or that result from an interaction between several disciplines. Therefore, most delegation heuristics are methods to prolong troubleshooting: First, you send the wrong person to work on troubleshooting, who then cannot easily get rid of the job. This is the ideal method to ensure that good old finger-pointing returns to the project culture.
In properly practiced DevOps, everyone on the team is responsible for everything you’ve collaboratively produced. Therefore, everyone should survey a production shutdown and then decide together who is best to continue taking care of the problem.
Pitfall 5: 80-to-20 principle in test and production
A derivation of the Pareto principle suggests that 80 percent of the effort for deployment and test automation requires only 20 percent of the effort for full automation. Naively, then, this means that you can actually achieve an 80 percent level of automation in a continuous delivery pipeline with relatively little effort. That, in turn, tempts you to neglect the last tedious 20 percent.
For automated regressions, this amounts to saying that 20 percent of all tests in the pipeline should still be performed manually. Of course, the cases that are especially difficult to automate (“80 percent of the effort”) are the ones left over. Either the initial state of the test is difficult to establish or the test process and result are easier to observe with human intelligence. Thus, a project consistently builds test debt (Fig. 4). As the number of features to be tested increases with each sprint, the number of additional manual tests also increases roughly proportionally. Gradually, the runs of the continuous delivery process lengthen or necessary regression tests are illegally dropped under the table. In the end, the DevOps project launched with hope suffers from a sort of ‘test mortgage’: it forces either a reduction in delivery frequency or a deliberately taken quality risk.
Even more insidious is the debt that a project with true continuous delivery ambitions incurs by not fully automating installations. DevOps, after all, promotes “code before documentation”: an administrator no longer needs to write an installation or action statement if he or she has stored an executable artifact for installation in the version control system. This often leads to a situation where, even with only 80 percent automation, administrators only produce code and no longer document anything. If a case from the missing 20 percent occurs (in which case, the pipeline will probably stop), yes, the author of the script can step in and fix the case by hand. While this is a form of job protection, it is not a healthy delivery strategy.
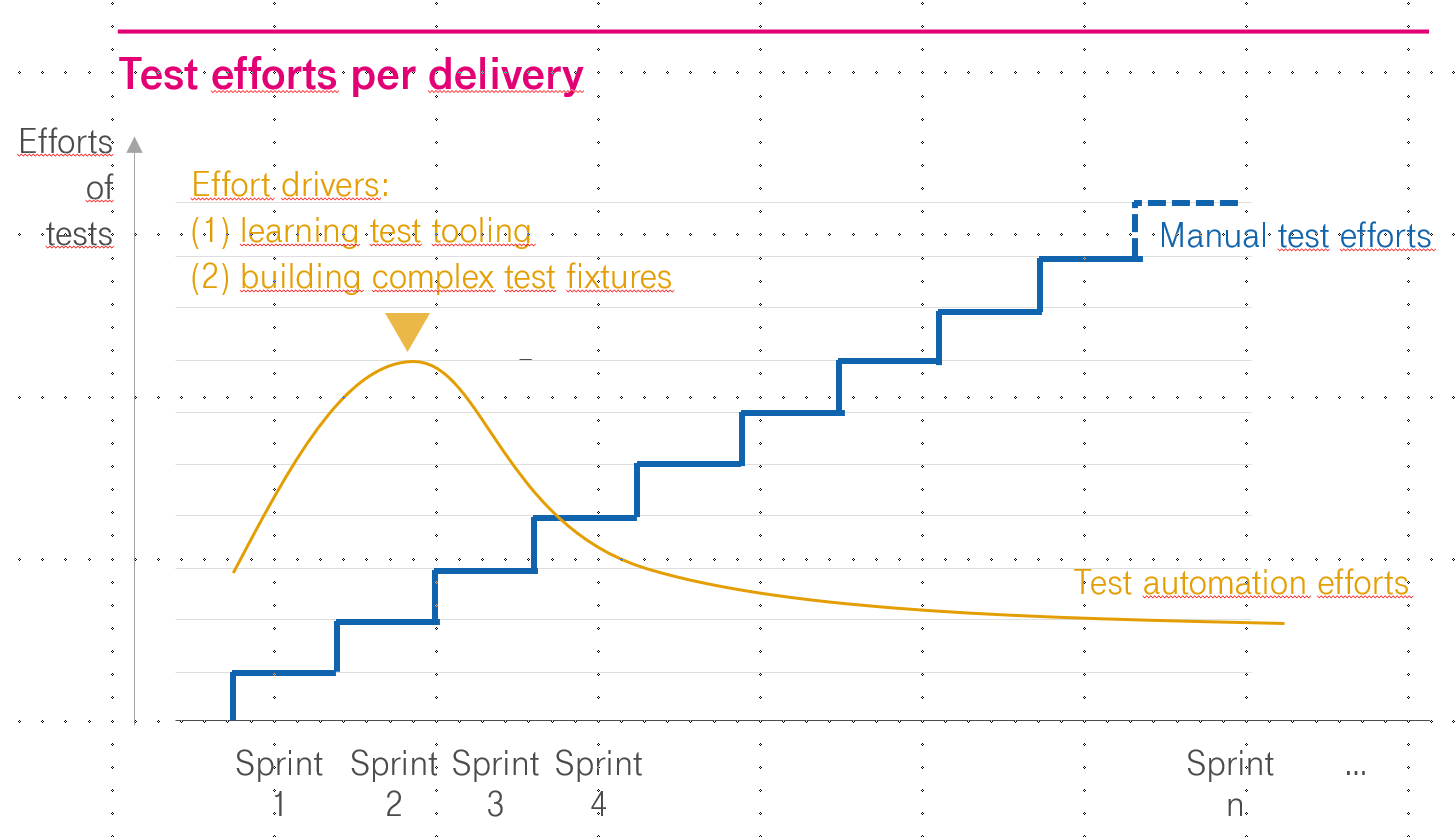 Fig. 4: Mortgage with test part automation
Fig. 4: Mortgage with test part automation
Pitfall 6: No zero downtime deployment
DevOps preaches continuous delivery of smaller changes (small batches). This ends up meaning much more frequent installations on the production environment.
It is still a widespread practice to take a customer system offline when you make a change. This becomes inconvenient if you want to deliver weekly or more frequently. Conversely, many projects with continuous delivery start with the claim of daily deployments. By then at the latest, downtimes are a perceptible, constant user annoyance and therefore no longer acceptable.
In continuous delivery, the automated supply chain builds a second (mirror) system alongside the production system (Fig. 5). Both run in parallel for a while until an administrator or an automated script finally switches to the new system.
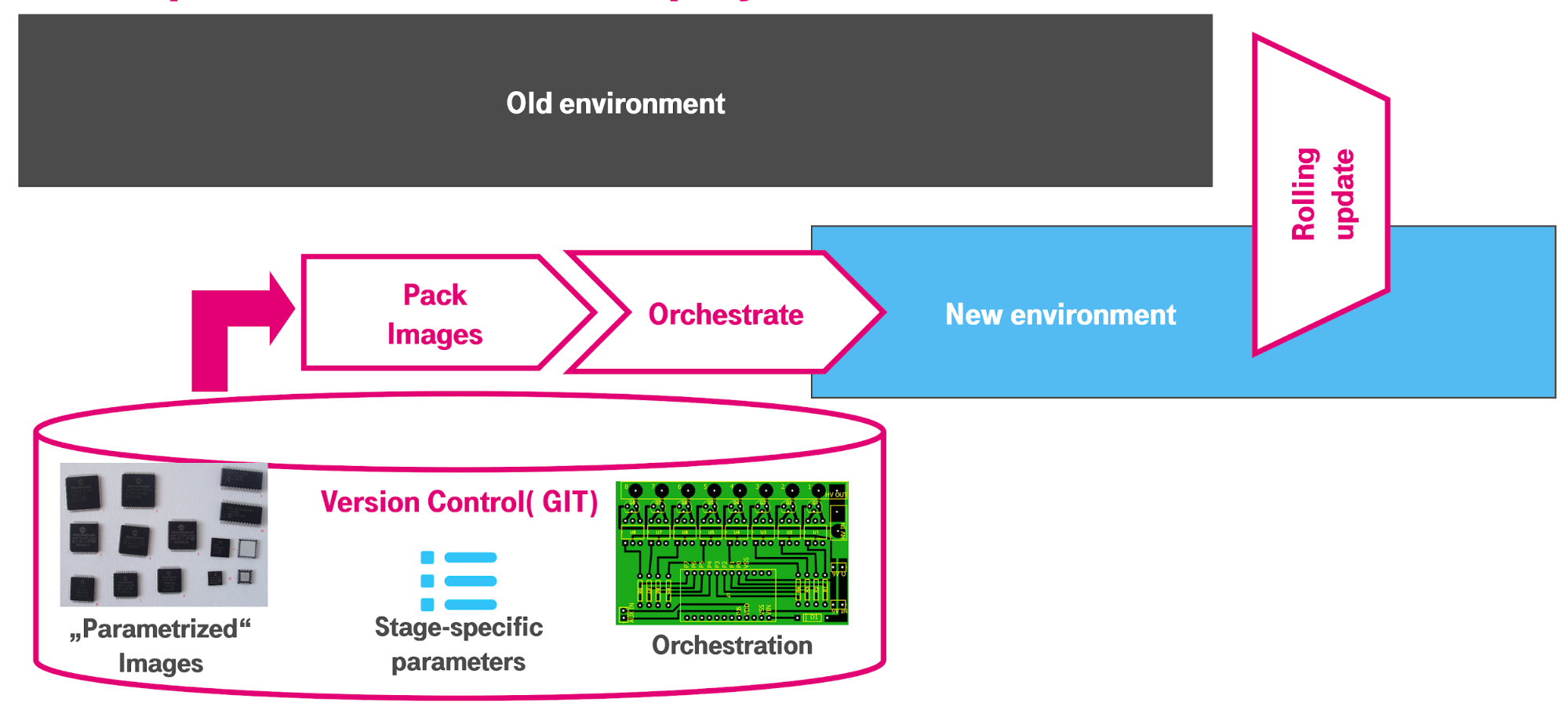 Fig. 5: Zero downtime deployments
Fig. 5: Zero downtime deployments
Supposedly smart product owners or project managers simply prohibit the last automated installation step in production. Instead, changes are collected before production and then rolled out to production as classic releases only a few times a year. This makes the team work fast for the product owner, but not noticeably faster for the outside world.
In fact, this approach is more like a deliberately missed penalty kick: The continuous delivery pipeline practices delivering individual, small changes quickly and reliably – in other words, reliably converting penalties. It is optimized for this purpose. For the production environment, the know-it-all ignores most of the improvements and prefers to kick a large package again, just as in the past. But it is still highly unlikely to sail smoothly into the goal.
Pitfall 7: No real cloud installation
An uninterrupted delivery needs two parallel running environments for a (short) period of time. If the project has a reference test or staging environment, switching between this and the production system is also potentially possible in classic, dedicated infrastructures.
But projects with tight infrastructure budgets often have to do without uninterrupted delivery, even if they have built a cloud in the basement with supposedly state-of-the-art container technology. They simply can’t afford it.
There are no clouds in the basement, and many offerings in an organization or in the market merely carry that label. The generally accepted definition of cloud computing according to NIST [7] calls for five characteristics from a true cloud platform:
- Broadband network connectivity
- Measurable service and delivery capabilities
- Short-term elasticity
- Self-service delivery on demand
- Unlimited resources (as perceived from the outside).
In particular, the demand for (potentially) unlimited resources is not feasible for many in-house installations. For this, a lot of unused hardware would have to be invested into in advance. On the other hand, servers can be rented for just a few hours on real cloud offers. A few euros can go a long way – and this flexible availability of resources is crucial.
If, for example, too few test environments are available, a bottleneck occurs. Unfortunately, delays occur precisely when many changes have to go into production at short notice under time pressure. Then the queues fill up with urgently needed new installations and updates in front of the environments, and in the end, the delivery frequency of the continuous delivery pipeline drops.
Sometimes inexperienced DevOps folks overlook the fact that non-disruptive switching should also be practiced. This also requires more infrastructure on test environments for a relatively short period of time.
On the other hand, if one ignores the importance of dynamic demand coverage and assigns a higher priority to an environment in one’s own possession, experience has shown that it is not at all uncommon for even a well-built Kubernetes cluster of one’s own to suddenly run out of resources at the most inopportune moment. To remedy this, there is really nothing left to do but purchase more computers, main memory, data storage, or better network connections. By then, at the latest, it is clear that you need a working environment that you can “top up” at any time at the push of a button and don’t have to wait for ordering processes. You need a real cloud.
STAY TUNED
Learn more about DevOpsCon
Know-how and experience are more valuable than licenses
The list of continuous delivery pitfalls presented is certainly not exhaustive. But it shows that buying the hottest and most expensive tools combined with healthy half-knowledge is unlikely to get you very far. Instead of this cargo cult, it is better to create an environment in which inexperienced teams are given the necessary space to gain experience. Experienced teams should be allowed to continue learning on an ongoing basis. Efficient teams are a treasure that money really can’t buy. Hero experts are out of (or, at least, on the way out) the room.
Links & Literature
[1] https://www.youtube.com/watch?v=CKAhYhij0og
[2] Kim, Gene: “The Unicorn Project. A Novel about Developers, Digital Disruption, and Thinking in the Age of Data”; IT Revolution Press, 2019
[3] https://cloud.google.com/solutions/devops/devops-tech-trunk-based-development
[4] https://puppet.com/resources/report/2014-state-devops-report/
[5] https://blog.item24.com/schlanke-produktion/jidoka-definition-ursprung-und-vorteile/
[6] https://en.wikipedia.org/wiki/Pareto_principle
[7] https://csrc.nist.gov/publications/detail/sp/800-145/final



