

As organizations move to become more “data-driven” or “AI-driven”, it’s increasingly important to incorporate data science and data engineering approaches into the software development process to avoid silos that hinder efficient collaboration and alignment. However, this integration also brings new challenges when compared to traditional software development. These include:
A higher number of changing artifacts. Not only do we have to manage the software code artifacts, but also the data sets, the machine learning models, and the parameters and hyperparameters used by such models. All these artifacts have to be managed, versioned, and promoted through different stages until they’re deployed to production. It’s harder to achieve versioning, quality control, reliability, repeatability and audibility in that process.
Size and portability: Training data and machine learning models usually come in volumes that are orders of magnitude higher than the size of the software code. As such they require different tools that are able to handle them efficiently. These tools impede the use of a single unified format to share those artifacts along the path to production, which can lead to a “throw over the wall” attitude between different teams.
Different skills and working processes in the workforce: To develop machine learning applications, experts with complementary skills are necessary, and they sometimes have contradicting goals, approaches, and working processes:
- Data Scientists look into the data, extract features and try to find models which best fit the data to achieve the predictive and prescriptive insights they seek out. They prefer a scientific approach by defining hypotheses and verifying or rejecting them based on the data. They need tools for data wrangling, parallel experimentation, rapid prototyping, data visualization, and for training multiple models at scale.
- Developers and machine learning engineers aim for a clear path to incorporate and use the models in a real application or service. They want to ensure that these models are running as reliably, securely, efficiently and as scalable as possible.
- Data engineers do the work needed to ensure that the right data is always up-to-date and accessible in the required amount, shape, speed, and granularity, as well as with high quality and minimal cost.
- Business representatives define the outcomes to guide the data scientists’ research and exploration, and the KPIs to evaluate if the machine learning system is achieving the desired results with the desired quality levels.
Continuous Delivery for Machine Learning (CD4ML) is the technical approach to solve these challenges, bringing these groups together to develop, deliver, and continuously improve machine learning applications.
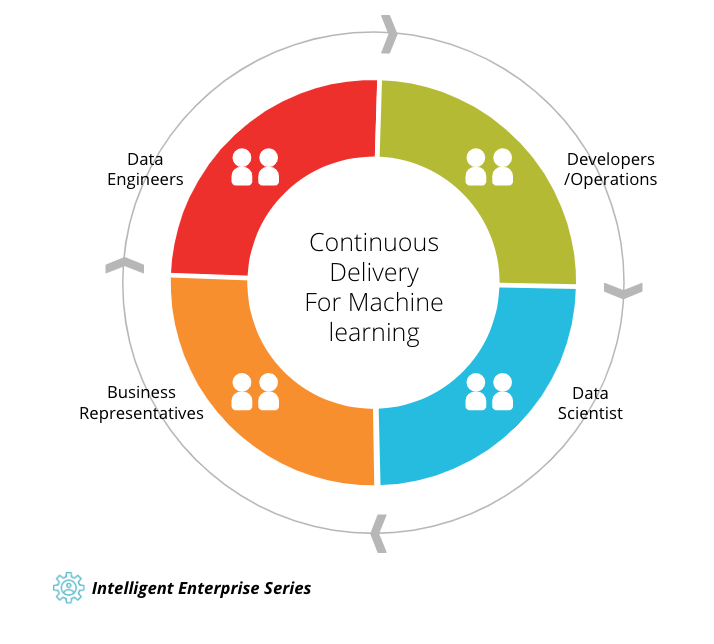
Figure 1: Continuous Delivery for Machine Learning (CD4ML) is integrating the different development processes and workflows of different roles with different skill sets for the development of machine learning applications
The Continuous Intelligence Cycle
In the first article of The Intelligent Enterprise series, we introduced the Continuous Intelligence cycle (see figure 2).

Figure 2: The Continuous Intelligence Cycle
This is a fundamental cycle of transforming data into information, insights and actions that support an organization as it moves towards data-driven decision making. In traditional organizations, this cycle relies on legacy systems (e.g. data warehouses, ERP systems) and human decision making. In these organizations, the process is slow and contains many friction points: machine learning applications are often developed in isolation and never leave the proof of concept phase. If they make it into production, this is often a one-time ad-hoc process that makes it difficult to update and re-train them, leading to stale and outdated models.
Intelligent Enterprises implement ways to speed up the Continuous Intelligence cycle and remove the different friction points along the way. CD4ML is the technical approach to accelerate the value generation of machine learning applications as part of the Continuous Intelligence cycle. It enables you to move from offline or bench models and manual deployments; to automate the end-to-end process of gathering information and insights out of data; to productionize decisions and actions based on those insights; and collect more data to measure the outcomes once actions have been taken. This allows the Continuous Intelligence cycle to run faster and produces higher quality outcomes at lower risks by allowing feedback to be incorporated into the process.
What is CD4ML?
To understand CD4ML, we need to first understand Continuous Delivery (CD) and where its principles originated. Continuous Delivery, as Jez Humble and David Farley defined it in their seminal book, is: “… a software engineering approach in which teams produce software in short cycles, ensuring that the software can be reliably released at any time”, which can be achieved if you “…create a repeatable, reliable process for releasing software, automate almost everything and build quality in.”
They also state: “Continuous Delivery is the ability to get changes of all types — including new features, configuration changes, bug fixes, and experiments — into production, or into the hands of users, safely and quickly in a sustainable way.”
Changes to machine learning models are just another type of change that needs to be managed and released into production. Besides the code, it requires our CD toolset to be extended so that it can handle new types of artifacts. What’s more, the whole process of producing software in short cycles becomes more complex because there is more variety in the team’s skill sets (data scientists, data engineers, developers and machine learning engineers), with each following different workflows.
ThoughtWorks has further developed the Continuous Delivery approach to overcome these challenges to be applicable to machine learning applications and calls this new approach Continuous Delivery for Machine Learning (CD4ML). It allows us to extend the Continuous Delivery definition to incorporate the new elements required to speed up the Continuous Intelligence cycle:
Continuous Delivery for Machine Learning (CD4ML) is a software engineering approach in which a cross-functional team produces machine learning applications based on code, data, and models in small and safe increments that can be reproduced and reliably released at any time, in short adaptation cycles.
This definition contains all the basic principles:
Software engineering approach. It enables teams to efficiently produce high quality software.
Cross-functional team. Experts with different skill sets and workflows across data engineering, data science, development, operations, and other knowledge areas are working together in a collaborative way emphasizing the skills and strengths of each team member.
Producing software based on code, data, and machine learning models. All artifacts of the software production process (code, data, models, parameters) require different tools and workflows and must be managed accordingly.
Small and safe increments. The release of software artifacts is divided into small increments, this provides visibility and control around the levels of variance of the outcomes, adding safety into the process.
Reproducible and reliable software release. The process of releasing software into production is reliable and reproducible, leveraging automation as much as possible. This means that all artifacts (code, data, models, parameters) are versioned appropriately.
Software release at any time. It’s important that the software could be delivered into production at any time. Even if organizations don’t want to deliver software all the time, the fact is that being ready for release makes the decision about when to release it a business decision instead of a technical decision
Short adaptation cycles. Short cycles means development cycles are in the order of days or even hours, not weeks, months, or even years. To achieve this, you want to automate the process — including quality safeguards built in. This creates a feedback loop that enables you to adapt your models as you learn from their behavior in production.
How it all works together
CD4ML aims to automate the end-to-end machine learning lifecycle and ensures a continuous and frictionless process from data capture, modeling, experimentation, and governance, to production deployment. Figure 3 gives an overview of the whole process.
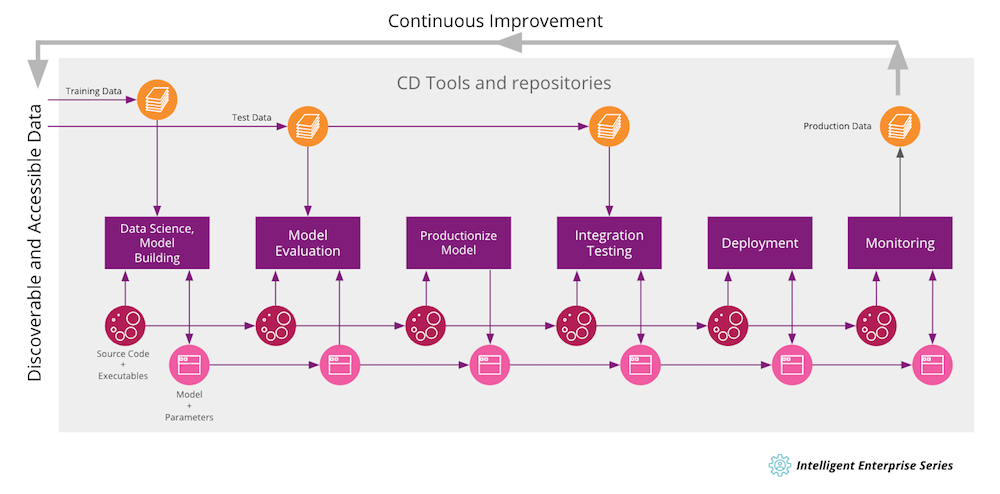 Figure 3: Continuous Delivery for Machine Learning in action
Figure 3: Continuous Delivery for Machine Learning in action
Starting at the left side of the cycle, data scientists work on data they discover and access from data sources. They wrangle the data, perform feature extraction, split the data into training and test data, build data models and experiment with all of them. They write code to train the models (often in Python or R) and tune them by choosing parameters and hyperparameters.
As these models are trained, the data scientists are constantly evaluating them. This means looking at the model’s error rate, the confusion matrix, the number of false positives and false negatives, or running certain test scripts — for example, for chatbots. The tests should be as automated as possible with the help of test environments, test scripts or test programs.
Once a good model is found, it’s ready to be productionized. The model has to be adapted to the production environment. This could mean containerization of the model code or even transforming it to a high-performance language like Java or C++ — either manually or using automatic transformation tools. The productionized version of the model has to be tested again in conjunction with other components of the overall architecture before it can be deployed to production.
In production, we have to observe and monitor how the model behaves “in the wild”. Metrics like usage, model input, model output, and possible model bias are important information about the model performance. This data can be fed back to the first stage of the process to enable further improvement: the whole Continuous Intelligence cycle starts again.
The transportation of the artifacts (source code, executables, training, and test data or model parameters) between the different process stages is controlled via pipelines that are executed by a CD orchestration tool. Every artifact is versioned, enabling reproducibility and auditability, so prior versions can be rebuilt or redeployed if required. The CD orchestration tool ensures the smooth and frictionless operation of the whole process and also allows governance and compliance, so certain quality standards and fairness checks are built into the process.
CD4ML in Action
We want to demonstrate the approach in practice based on a real client project delivered by ThoughtWorks. In fact, our current notion of CD4ML first emerged several years ago when we first applied Continuous Delivery to a user-facing machine learning application. You can read about it in detail here.
Our challenge was to build a price estimation engine for a leading European online car marketplace. The engine needed to be able to give a realistic estimate for anybody looking to buy or sell a car. That price estimate would be based on past car sales within the marketplace. As the market for used cars is constantly changing, the price estimation model has to be continuously re-trained on new data. A perfect case for CD4ML.
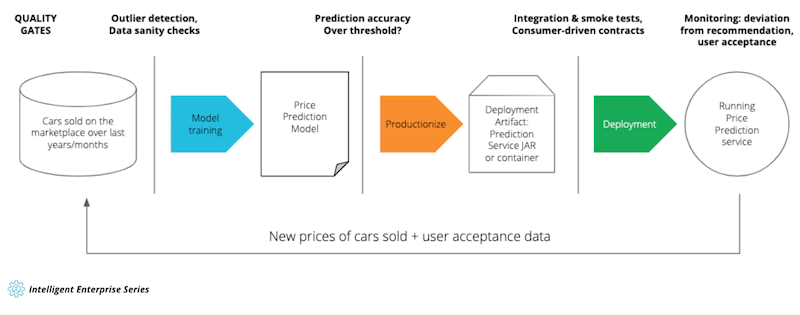
Figure 4: A CD4ML end-to-end process in a real-world example
Figure 4 shows the overall CD4ML flow for this specific case. The data scientists train the model using data from the marketplace — such as car specs, asking price and actual sales price. The model then predicts a price based on the car model, age, mileage, engine type, equipment, etc.
Before training a model, there’s a lot of data cleanup work to be done: detecting outliers, wrong listings, or dirty data. This is the first quality gate to be automated — is there enough good data to even provide a prediction model for a certain car model?
Once the trained model can make sufficiently accurate price estimates, it’s exported as a productionizable artifact, — a JAR or a pickle file. This is the second quality gate: is the model’s error rate acceptable?
This prediction model is then transformed into a format matching the target platform, then packaged, wrapped, and integrated into a deployable artifact — a prediction service JAR containing a web server or a container image that can be readily deployed into a production environment. This deployment artifact is now tested again, this time in an end-to-end fashion: is it still producing the same results as the original, non-integrated prediction model? Does it behave correctly in a production environment, for instance, does it adhere to contracts specified by other consuming services? This is the third quality gate.
If all three quality gates succeed, a new re-trained price prediction service is deployed and released. Importantly, all of those steps should be automated so that re-training to reflect the latest market changes happens without manual intervention as long as all quality gates are satisfied.
Finally, the live price prediction is continuously monitored: how do the sellers react to the price recommendations? How much is the listing price deviating from the suggestion? How close is the price prediction to the final buying price of the respective vehicle? Is the overall conversion and user experience being impacted, for instance by rising complaints or direct positive feedback? In some cases, it makes sense to deploy the new model next to the old version to compare their performance. All this new data then informs the next iteration of training the prediction model, either directly through new data from cars that were sold or by tweaking the model’s hyperparameters based on user feedback, which closes the Continuous Intelligence cycle.
Opportunities of CD4ML and the road ahead
Adopting Continuous Delivery for Machine Learning creates new opportunities to become an Intelligent Enterprise. By automating the end-to-end process from experimentation to deployment, to monitoring in production, CD4ML becomes a strategic enabler to the business. It creates a technological capability that yields a competitive advantage. It allows your organization to incorporate learning and feedback into the process, towards a path of continuous improvement.
This approach also breaks down the silos between different teams and skill sets, shifting towards a cross-functional and collaborative structure to deliver value. It allows you to rethink your organizational structures and technology landscape to create teams and systems aligned to business outcomes. In subsequent articles in the series, we’ll explore how to bring product thinking into the data and machine learning world, as well as the importance of creating a culture that supports Continuous Intelligence.
Another key opportunity to implement CD4ML successfully is to apply platform thinking at the data infrastructure level. This enables teams to quickly build and release new machine learning and insight products without having to reinvent or duplicate efforts to build common components from scratch. We’ll dedicate an entire article to the technical components, tools, techniques, and automation infrastructure that can help you to implement CD4ML.
Finally, leveraging automation and open standards, CD4ML can provide the means to build a robust data and architecture governance process within the organization. It allows introducing processes to check fairness, bias, compliance, or other quality attributes within your models on their path to production. Like Continuous Delivery for software development, CD4ML allows you to manage the risks of releasing changes to production at speed, in a safe and reliable fashion.
All in all, Continuous Delivery for Machine Learning moves the development of such applications from proof-of-concept programming to professional state-of-the-art software engineering.
This article was first published on ThoughtWorks.com





















































