
If I had to choose one concept that has really captured my attention in the last couple of years it would probably be ‘liquid software’. Coined by Fred Simon, Baruch Sadogursky and Yoav Landman of JFrog it refers to “high quality applications that securely flow to end-users with zero downtime”. In the book with the same name they describe the world of a near future, where code updates are being poured continuously into all kinds of deployment targets – web servers, mainframes, mobile phones, connected cars, or IoT devices. I must admit I’ve always been abnormally excited by this notion of information flowing freely, without restrictions and borders. This is probably impacted by the fact I grew up in the Soviet Union, where information was held hostage, passed around in whispers. Where it was a bomb waiting to explode. And then it did all blow up – exactly as I was turning into a teenager. Perestroika arrived to set the information free, and my young heart on fire. So yes, I’m an information freedom junkie, don’t blame me for that.

The Platform for Distributed Trust
But personal biases aside – the information revolution has changed how our world operates. In this increasingly connected world, we can no longer rely on central, institutional authorities to get our information. Rachel Botsman wrote a great book called ‘Who Can you Trust’ which talks about the evolution of trust in human society. In the book she shows how trust has graduallydeveloped from local – as in prehistoric societies – to institutionalized and centralized. And how we are witnessing the fading of centralized trust as it is replaced by the distributed model. A model in which we trust an AirBnB house owner on the other side of the globe just because there are a couple dozen more folks on the internet who put the same trust in her.
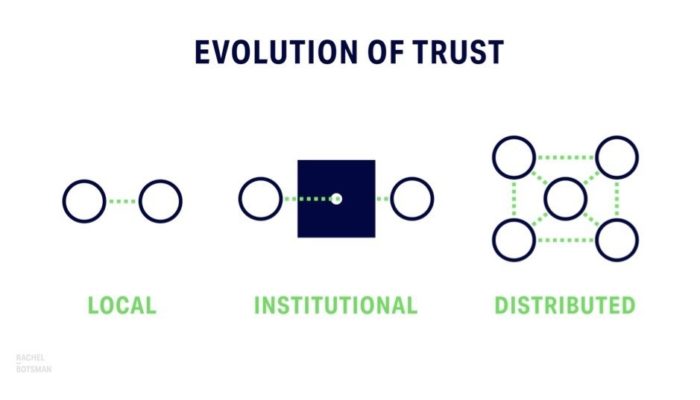
Guess what enables this distribution of trust? You’re right, information technology, of course! And yes, that information technology must be both up to date and working at any given moment, please. 24/7 – 365 days a year.
There’s a problem, though. Not only are modern execution platforms increasingly distributed, they are also fragmented and heterogenous. We’ve only grown somewhat accustomed to the complex, fluid, ephemeral world of microservice architectures, and now we also need to support the event-driven paradigms of serverless and edge computing. How can we roll out continuous updates with certainty when there’s a scary, chaotic world full of unexpected events waiting for our code out there?
Progressive Delivery
But let’s take a step back and remind ourselves why we need all this complexity in the first place.
There are three main driving forces behind splitting our monolithic applications into microservices, and further into ephemeral functions and edge deployments: scalability, resilience, and continuous delivery. Large monoliths are quite bad at all 3 of them, while service-oriented systems supposedly promise to give us all three. I say supposedly because this trinity also exists in eternal mutual tension. Continuous delivery and scaling are relentlessly changing the logic and configuration of the system – putting its resilience under constant stress. On one hand, scalability can be seen as a feature of resilience, on the other, it makes a system more complex and thus more brittle. Features that provide us robustness (robustness and resilience aren’t the same, but they do share several qualities) can also cause resistance to change. And what is especially important for today’s subject is that horizontal scalability makes all our systems – no matter if they run in the cloud – increasingly dependent on the network tissue, which has now become the main integration point. This is where our components meet and also where they meet the external services they interact with… I’m not sure if this distinction even matters anymore. True resilience requires treating all services like strangers bound with a clear official contract – no matter whether they are internal or external. And the resulting crazy interdependence matrix turns continuous delivery into an equation with a multitude of unknowns.
The necessity to provide ongoing updates under these unpredictable conditions is making release safety practices such as blue-green deployments, canary releases, dark launches, and traffic mirroring ever more relevant. We need them both to keep our systems running and to keep our engineers sane. Thanks to James Governor there’s now even a new umbrella definition for all these techniques: progressive delivery. I.e. the type of delivery that allows us to gradually pour new freshly brewed liquid software into the data pools, lakes, and seas.
But it suddenly becomes very hard to implement progressive delivery when our main integration point is this dumb, unreliable, inflexible network tissue.
Service Mesh To The Rescue
Service mesh is a relatively new software architecture pattern that allows us to insert smarts into this integration layer. Pioneered by Linkerd and further developed and enhanced by Istio, it involves infiltrating the network with a mesh of smart proxies that intercept all data paths. There’s been some debate as to whether making the network smart goes against one of the main principles of microservices: smart endpoints, dumb pipes. But the general agreement seems to be that it’s ok to make the network more intelligent as long as we don’t put business logic in it.
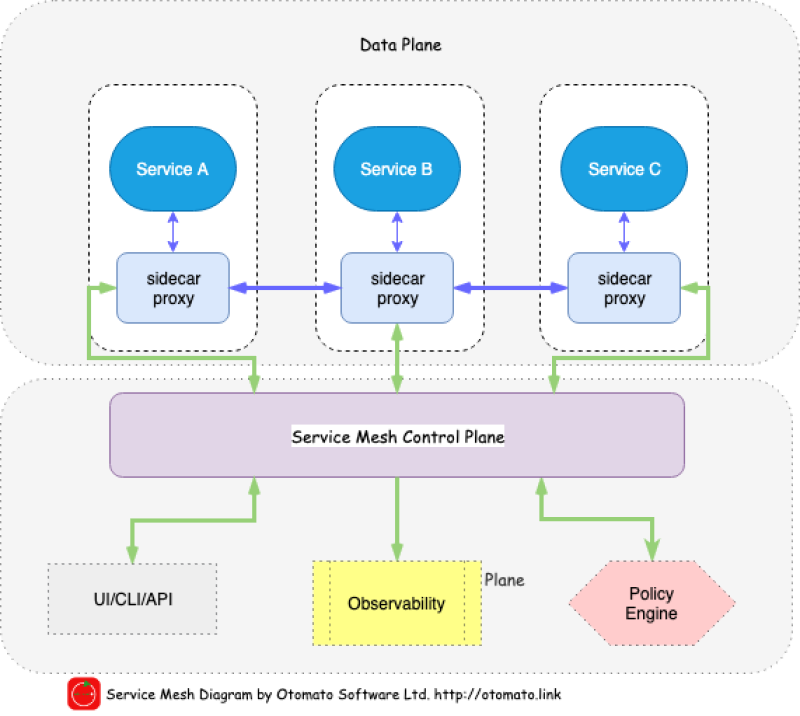
And well – it’s hard to withstand the temptation. Smart networks provide some significant perks. Increased centralized observability of the communication layer, distributed tracing, end-to-end mutual TLS, and yes – all the advanced intelligent routing and error injection techniques one might need for implementing true progressive delivery all across the stack. Some of these require virtually no effort. E.g. Istio, Linkerd and, of course, all cloud providers’ offerings have an option to include the observability stack out of the box. At the click of a button everybody gets
what they want: operators – visibility and control, developers – freedom from the fallacies of distributed systems, and the business – agility, stability, and continuous change.
Do I Need a Service Mesh?
Service mesh sounds wonderful, doesn’t it? But you know what came to my mind when I first heard of it? “Oh, gosh, we haven’t passed through all nine circles of Kubernetes yet, what do we need another level of complexity for?”
A similar emotion is quite well illustrated by the following tweet:

And I’ve talked to quite a bunch of folks sharing the same sentiment. Yes, a while later, when we dove deeper into the technology we’ve found a number of use cases where Istio has provided tremendous value. Especially in all that pertains to progressive delivery. But that may be because effective software delivery is our main focus. I’m sure security and compliance folks will love meshes for all the different reasons.
So do you need a service mesh? I’ll give you the usual, annoying “it depends”. You will probably benefit from it if you’re running a service-oriented system but have hard time reaping its benefits: resilience, scalability and continuous delivery. If your bottlenecks are somewhere else (and they often are) – service mesh will only make things more complex. The mesh takes some control from the hands of developers and puts it in the hands of operators. So if you’re trying to run a no-ops kind of shop, you may be better off sticking with libraries (like Finagle or Hystrix) instead. And certainly ask yourself if you’re happy with your organization’s ability to release changes to production and run experiments. If you feel like you should be doing better – service mesh may be just the way to achieve canaries, a/b testing or error injection and allow for stress-free releases.
Service meshes are all the buzz. Our Istio workshop at DevOpsCon Berlin was sold out pretty fast, but if you’d like to see Istio in action – we can probably arrange running a workshop at DevOpsCon Munich later this year 😉
See you soon at the conference.
Happy progressive delivering.






















































